DOI: 10.31038/JMG.2020331
Abstract
In classical biology, different taxonomic categories are all decided based on empirical rules established on learning knowledge. In taxonomy, different classification systems are of diversified rules. Biology is often in different categories, although the concepts related to taxonomic categories are the same to each other. Whether there exist some absolute standards to classify biology, and to give unalterable results. This is of greatly scientific meaning. Common and variation, that is heredity and variation are the most elemental information in biology, and exist at multiply biology material levels. In this paper a generalized biological heredity and variation information theory was proposed based on previous works. Three typical heredity and variation models were analyzed by using this theory. They are unique asymmetric variation model, symmetric two variation model and extreme radial variation model. In the maximum information states, two biological constants Pg1= 0.69 and Pg2= 0.61 and a boundary similarity function 1/lnNdwere obtained. These Pg and Pg function can be defined as the three theoretically taxonomic category criteria of biological system. For 29 samples belonging to four kind plants, their chemical fingerprint-infrared (IR) fingerprint spectra (FPS) were analyzed depending on the theoretical criteria. The correct classification ratio was 96.6%. The results showed these samples could be ideally classified. A suggestion was proposed that biology should be absolutely classified relying on the three intrinsic theoretical criteria.
Keywords
Heredity and variation information, Genetics, Theoretical category, Taxonomy, Classification, Close relative, Medical plant, Fingerprint spectra
Introduction
Presently, taxonomy is a far from finished basically scientific research. All taxonomic categories are the classification grades in modern biology. These categories include Species, Genus (Genus), family (familia), Order (Ordo), Class (Classis), Phylum (Divisio), Kingdom (Regnum), which are all empirical rules determined relying on learning knowledge. In these rules, there is short of rigidly quantitative standards. Moreover, it lacks the support of mathematical principles. Currently, we can ask a question whether these categories really exist in biology, or whether there are some theoretical categories or grades in biology system. If some theoretical categories are deduced from some mathematical theories, whether they can correspond to taxonomic categories obtained by empirical knowledge, and whether these theoretical categories can be confirmed by experiments.
As we well known, biological common/heredity and variation are the most elemental information of biology, and exist at many material levels, including both biologically small molecules, macro- molecules, molecular structure, cell, organelle, organ, and individual, population, species and other higher levels, including Genus (Genus), family (familia),Order (Ordo), Class (Classis), Phylum (Divisio), Kingdom (Regnum). These can be named generally biological heredity and variation information. Whether a theory can be built up to describe generally biological heredity and variation information, to reveal some elemental laws and some particular laws, so as to classify biology accurately. This is a core theoretical problem in biological science. Research on common/heredity and variation information is the theoretical base of taxonomical science.
More than a century, the most important heredity and variation theory is population genetics [1-4] established grounded on Mondel laws and Hardy-Wenberger law at gene level in DNA sequence of the same biological species. In population genetics, the combination patterns or genotypes of allele and their distribution frequencies are investigated, and then their accompanying traits are researched. The effects of multiple genes on a biological characters are investigated too [5-9]. However, there is a short of study on heredity and variation laws at single base and base segments levels in DNA sequences so far.
Presently, statistical genetics and bioinformatics are the major theories to analyze heredity and variation at biological macro-molecule level besides population genetics. In bioinformatics, various variations are analyzed by sequence alignment, through comparing differences of structure units, such as single base in DNA, RNA sequences, various sequence segments in different genes, gene pools, and amino acid in protein sequences [8,10-15]. Grounded on above analysis, different kind phylogenetic trees of different biological samples, such as genes, proteins, organisms in different populations and species, can be achieved. Then taxonomy, classification, identification and cluster of biological individuals, genes, proteins are performed empirically [16- 25]. In these methods, only the difference information are accepted to form empirical theories. While these methods are not able to reach a unchangeable result, which can outline the accurate laws, and do not vary with samples. Biological laws should be determined by common property of biology, so it is impossible to achieve the accurate law merely depending on variations.
For a long time, in biological science, there is no any accurate theory to deal with both common/heredity and variation simultaneously at any material level. Recently, it is necessary to built up the heredity and variation theory grounded on multiple material levels, such as molecule, cell, organ, individual and population, in order to describe unalterable heredity and variation laws.
How can we build up a theory to discover the intrinsic laws of common and variation. As well known, biological system is a physical chemistry system composed of thousands of substances. For a physical chemistry system, its physical chemistry action is in relatively steady states with certain action characteristics, which determine biological characteristics objectively. In modern biological science, biological chemistry reactions are investigated completely based on physical chemistry at molecular levels, and some simple movement rules are revealed at cell level [26-29].
On the other hand, as we well known, Shannon’s information theory suits to describe random system, but can not precisely represent a nonrandom system, such as biological system.
Theoretically speaking, a correctly general heredity and variation information theory should be grounded on physical chemistry action of heredity and variation substances, that is common heredity action and variation action. Author ZOU has deeply investigated this subject and proposed a theory, biological common heredity and variation information equation based on simple physical chemistry action model of heredity and variation substances [30]. Relying on the previous research fundamental [30-35]. In this paper a generalized biological common heredity and variation information equation was further built up, theoretically which is qualified to describe heredity and variation at multiply material levels, such as various material structure units, biological molecules.
Based on the generalized biological common/heredity and variation information theory, three kind typical heredity and variation types were analyzed. Two biological constants and a boundary similarity function were obtained, which correspond to some biological categories. They can be defined as the theoretically taxonomic categories, and are tested by experiments in this research. The infrared fingerprint spectra, a kind of chemical fingerprint spectra of 29 samples of four kind medical plants were measured and analyzed. They could be divided into four classes ideally depending on these criteria, and their close relatives were correctly analyzed too.
The study showed these theoretical categories may correspond to some species, or to some genus, or other empirical categories. The boundary similarity function can be easily used as a rigid standard to determine which plants belong to close relative.
Methods
Instrument
Vector 22 FT-IR (Bruker scientific technology Co., Ltd., Germany), spectra range:4 000 cm-1-400 cm-1, Resolution 4 cm-1. High speed mill,
Analytical balance (METTLE TOLEDO), sensitivity 0.1 mg. Soxhlet extractor. Hot water bath.
Reagent
Chloroform (AR), ethanol (AR) (Kemiou chemical regent limited company, Tianjin, China ).
Preparation of samples and measurement condition
To dry the root samples of 29 plants at 60°C for 2 hours, then to grind these dried roots into powders and sieve these powders with 60 mesh. 2.00 g powders (3 parallels for each sample)of one sample were taken and wrapped with filter paper, which was put into soxhlet extractor. Then 50 ml of chloroform was put into the extractor. To extract sample for 2 hours at boiling point of chloroform, and pour out the extracted solution, in order to extract little of liposoluble substances.
The residual chloroform solved in powders was evaporated clearly by using hair dryer with hot air for 5 minutes. Then to put 60 ml of absolute ethanol into Soxhlet extractor, and extract sample for 1.5 hours. The extraction was poured out into an evaporator on hot water bath at 80°C, till the solvent was evaporated clearly.
After this above step, the dried extract was resolved by using dehydrated ethanol, treated with molecular sieve, to be a saturated solution. It was put into sample tube and kept at below 0°C.
The IR FPS of samples were measured with liquid film method based on KBr crystal flat. Each extract was measured three times, and each sample with three parallel extracts, then 9 IR FPS were yield. To take the mean wavenumbers of each group of common peaks in these 9 IR FPS as a combination peak, all combination peaks of a sample form its combination IR FPS. Then all combination IR FPS of these 29 samples were compared to form multiple groups of common peaks, which were analyzed by means of the approach showed in this paper. The sensitivity of vector 22 FT-IR was 2. For extracts kept at 0~4°C, they were of good repeatability.
Software
All data were analyzed by means of the software written by my students.
To establish generalized biological heredity and variation information theory
Heredity/common and variation wildly exist at many material levels, and result in generating and extincting of many biological systems. Because of the extreme complexity in biodiversity, which has a vast of variables, factors, the development in heredity and variation theory was limited greatly.
Whether there is a general theory to describe them? Author ZOU once investigated this subject based on physical chemistry principle systematically. Firstly, he independently defined and constructed the common peak (element, molecule) ratio Pg, and variation peak (element, molecule) ratio Pvi scientifically in biological classification field [36-39]. Then dual index grade sequence individual pattern recognition method was proposed [40,41], based on the two index. These researches proved that the two index Pg and Pvi are able to represent biological properties well. Grounding on these investigations, a novel theory was proposed to deal with common heredity and variation systematically.
Generalized biological heredity and variation information theory
Depending on common peak (element, molecule) ratio Pg, and variation peak (element, molecule) ratio Pvi, author ZOU first proposed common heredity and variation information theory, that is dual index information theory, or heredity and variation information theory in 2009 [30]. The equation was as follows. When there are two kind variations a, b, corresponding to two samples in a biological system,
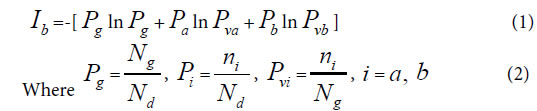
Generally, in the analysis of a sample set, one sample corresponds to one class of variation. If there are many kind variations in a biological system with a sample set, how to describe the action information. So a generalized equation need to be built up. Suggest there are m kind variations in a biological system, and each kind variation contain nielements or variables, then the generalized biological heredity and variation information equation was represented as follows.
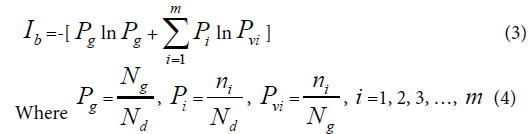
The meanings of variables in the equation (3), (4), as in [30-35] were listed below.
Pg, common (heredity) peak (element, molecule) ratio, it can be briefly expressed as P. This index is the same as the JaCcard and Sneath, Sokal coefficients.
Pi, the ratio of ni to Nd. Pvi is the variation peak (element, molecule) ratio of ni to Ng.
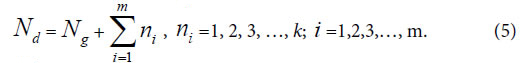
Nd , the independent peaks (elements, molecules) existed in a system.
Ng, common (heredity) peaks (elements, molecules) existed in a system.
ni , variation peaks (elements, molecules) belong to variation class i .
Relying on paper [30], – Pgln Pg represents the similarity action of the system based on common elements, and ![]() represents the action between common and variation elements. According to these generalized biological heredity and variation information equation, a biological system is usually of three typical variation models. They are listed below.
represents the action between common and variation elements. According to these generalized biological heredity and variation information equation, a biological system is usually of three typical variation models. They are listed below.
Considering multiple types of variation elements, there are three typical variation models.
Variation Model 1: n , =1, n >o, with only one variation class, the extreme asymmetric variation, or unique variation state in a system.
Variation Model 2: ni, i =1,2, and n1 = n2 >0, with two variation classes, or two symmetric variation states in a system.
Variation Model 3: ni=1, i =1, 2, 3, …, m, with m classes of
extreme radial variations. It means for each variation class, there is only one variation peak (element, molecule). This schematic was showed in Figure 1.
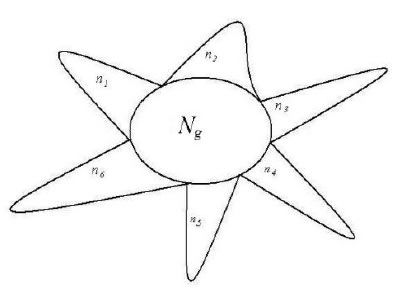
Figure 1. A system composed of Ng common heredity elements and ni variation elements, i =1, 2, 3,…, m. For example, This system poses 6 classes of variation elements.
A lot of experiments have proved that for equation (1), it is able to accurately reveal some significant properties in complex biological systems. Two similarity constants P = 0.69, P = 0.61, can be
obtained in the maximum information states. Pg1= 0.69 corresponds to the unique variation state, that is variation model 1. Pg2= 0.61
corresponds to symmetric variation state, that is variation model 2.
These two similarity constants can be proved in below section. Based on the two similarity constants, very complex biological systems-the combination herbal medicines (traditional Chinese medicine, TCM), which consist of extracts of many medical plants, could be classified accurately relying on IR fingerprint spectra, which reflect structure unit information of biological small molecules [30-32,35]. Genus and Subgenus of pine could be discriminated precisely depending on information of molecular species in oleoresins [33], and four species of combination herbal medicines [33,35] were identified perfectly by means of the two constants. Three kinds of soybeans, black, green and yellow soybean proteomes were pattern recognized subtly by using the constant Pg2=0.61, together with structure information of macro-molecules [34].
All these previous researches express that the primarily established heredity and variation information equation is qualified to uncover some heredity and variation laws of biology.
Similarity constants corresponding to Variation Model 1 and Variation Model 2
Similarity constant Pg1: When there is only single variation class, that is extreme asymmetric variation state, corresponding Variation Model 1. ni>0, i =1, n1 = Nd–Ng, generally biological heredity and variation information equation can be expressed as follows.
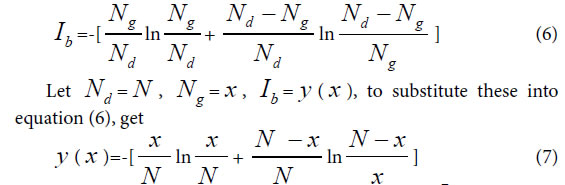
To take the derivative of equation (7), and let Ib to be in the maximum information state, then get

This equationghas a soglution P=0.692, approximately is 0.69=69%.
This theoretical standard has been successfully testified in researches [32,33,35]. Pg= 0.69 can be defined as similarity constant Pg1.
According to article [30-35], for any two samples in a sample set, we can view them is a biological system. Theoretically, when their Pg ≥ 69%, they are in the asymmetric variation state, and they are of the
identical properties. They belong to the same class. When their Pg < 69%, there are some distinct differences between them, they are not of identical property.
Similarity constant Pg2: In a biological system, when in symmetric mutation state, corresponding to Variation Model 2, n1 = n2 >0.
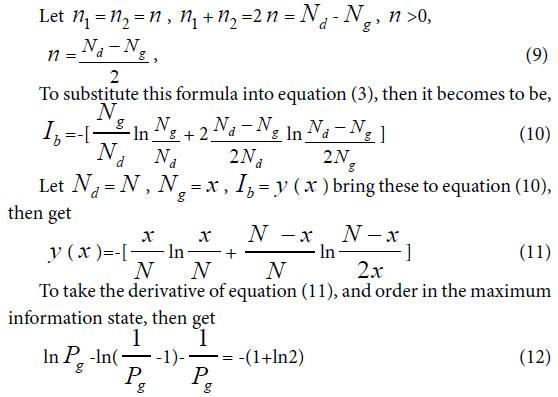
To solve this equation, one can obtain Pg=0.6085, approximately is 0.61= 61%. Pg= 61% can be defined as similarity constant Pg2.
According to article [30-35], for any two samples in a sample set, we can view them is a biological system. When their Pg ≥ 61%, they are of the identical properties, and they belong to the same class. when their Pg < 61%, there are some distinct differences between them, they are not of identical property.
In the same way, one can get,
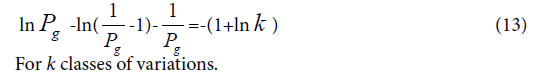
Boundary Similarity function corresponding to Variation Model 3
For extreme radial variation model, ni =1, i =1,2,3,…, m. that is all variation elements are different from one another. Each variation element belongs to its own class. In this situation, generally biological heredity and variation information equation can be represented as follows.

To take the derivative of equation (15), and let it to be in the maximum information state, then obtain,
Considered some degree of randomness of heredity and variation in biology, we can deduce a formula for accurately and briefly calculating the common peak (molecules, or any elements ) ratio Pg in biology,
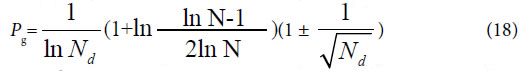
Since the theoretical criteria are similarity Pg, then these Pg show the ratios of common materials to total materials. The common characteristics reflect the identical properties, which are the ancestor characters of these samples in a biological system. So the value of Pg reflects high or low of ancestor traits between these samples. The higher the Pg, the closer the relative relationship of them. So to determine relative relationship far and near between samples relying on the high or low of Pg is scientifically reasonable.
Equation (17), (18) represent the relationship between Pg and N. That is there is no constant Pg in Variation Model 3. They are also the boundary condition or maximum variation range for close relatives, which originate from the same close ancestor. Since there is no limitation in the number and kinds of samples in a biological system, this theory is suitable for any open biological system.
The similarity function (17), (18) can be defined as the discrimination function of close relative biology. This function is the critical point for extreme variation of a biological system. For any two samples in a sample set, we can view them is a biological system. When their Pg < Prad, there are extremely distinct differences between them, they do not belong to close relative. Prad reflects the theoretical boundary of the close relative relationship.
Theoretically, these intrinsic criteria of Pg should be related to some biological ranks, that is theoretically taxonomic categories, such as species, genus, family and so on. Then these intrinsically characteristic Pg can be defined as differently theoretical criteria of some intrinsically taxonomic categories.
As we known, there are many biological levels or ranks, including species, genus, family as well as others in relative systems. Whether these ranks correspond to these Pg criteria for intrinsically taxonomic categories, or they can be theoretically discriminated by these criteria, previously classified by empirical knowledge. All these need to be verified by experiments.
Certainly, for the two constants, they may correspond to two intrinsically taxonomic categories, which should correspond to any two different biological ranks, such as species and subspecies, genus, subgenus, family and so on. These have been proved successfully by some researches [33,34]. These researches indicated the theoretically taxonomic categories, existed intrinsically in the equation, do not one-to-one correspond to empirical ranks of biology, obtained by means of empirical classification. From the view of scientific point, people should classify biology into some absolute ranks based on these theoretical criteria, and should offer strictly theoretical boundaries of close relatives.
Presently, The major methods in biological classification, cluster and pattern recognition are classical taxonomy [42-46], molecular taxonomy [16-25], Chemical taxonomy [42-44]. The major study manner is to discover new rules by means of experiments or depending on empirical knowledge, but not by some mathematical principles. On the other hand, many similarity and difference index were applied for the recognition, classification, cluster and evolution researches of traditional medical plants and combination herbal medicines, soybeans [30-32,34-41,47-52], depending on IR fingerprint spectra, one of the chemical fingerprint spectra, information of biological molecular structure units. This may be a good approach for building up new mathematical principles existed in biological ranks.
Classification of 29 medical plant samples based on three theoretical criteria
Plant samples
In this article IR fingerprint spectra of 29 plant samples were measured and analyzed, the experiments, seen Methods these samples belong to four kind medical plants: Baishao, Chishao, Huangqi, and Gancao. In these samples, Baishao, Chishao belong to Paeonia L.(genus), Huangqi belongs to Astragalus Linn.(genus), Gancao belongs to Glycyrrhiza Linn.(genus). The sources of these 29 samples were listed in Table 1.
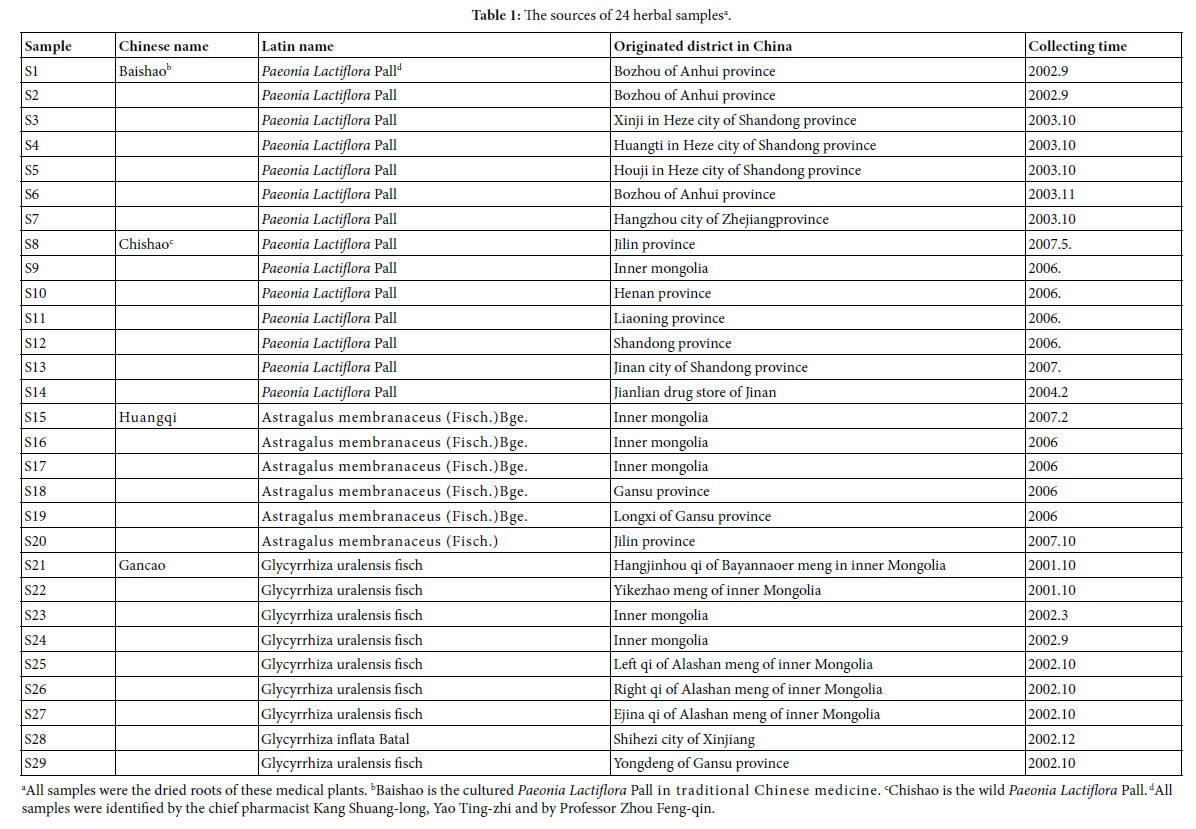
All samples were kept at bellow -18°C, after collected and dried.
Analysis on IR fingerprint spectra data of 29 plant samples
Determination and represent of common and variation peaks in IR fingerprint spectra: According to the methods to extract major compositions of samples with absolute ethanol, and to measure their IR fingerprint spectra. Then to determine the common and variation peaks of these IR FPS by means of Shapiro-Wilk test [53]. The common and variation peaks were listed in Table 2.

The averaged wavenumbers (cm-1) of all peaks are listed below:
± 6; 2,3406 ± 1; 3,3396 ± 2; 4,3385 ± 2; 5,3375 ± 3; 6,3363 ± 2; 7,2973 ± 1; 8,2928 ± 2; 9,2113 ± 2; 10, 2102 ± 1; 11,2090 ± 1; 12,1727 ± 3; 13,1714 ± 3; 14,1642 ± 1; 15,1635 ± 1; 16,1624 ± 2; 17,1615 ± 2; 18,1570 ± 1; 19,1512 ± 1; 20,1458 ± 1; 21,1450 ± 2; 22,1419 ± 1; 23,1408 ± 4; 24,1385 ± 4; 25,1372 ± 1; 26,1346 ± 3; 27,1333 ± 1; 28,1300 ± 1; 29,1278 ± 3; 30,1259 ± 1; 31,1252 ± 1; 32,1234 ± 1; 33,1227 ± 1; 34,1204 ± 1; 35,1131 ± 3; 36,1103 ± 2; 37,1073 ± 2; 38,1062 ± 1; 39,1051 ± 2; 40,1037 ± 1; 41,1029 ± 1; 42,997 ± 1; 43,938 ± 3; 44,926 ± 2; 45,892 ± 1; 46,880 ± 1; 47,871 ± 1; 48,856 ± 1; 49,835 ± 1; 50,821 ± 1; 51,777 ± 1; 52,714 ± 1; 53,667 ± 3; 54,632 ± 2; 55,623 ± 3; 56,613 ± 1; 57,596 ± 5; 58,582 ± 2; 59,553 ± 4; 60,526 ± 1. Peaks with the same code in different samples belong to a common peak group. There are 60 common peak groups or independent peaks in the 29 plant samples.
Characteristic sequences and classification of 29 plant samples
According to the two similarity constants Pg1= 69%, Pg2= 61%, obtained from generally biological heredity and variation information equation (3), and the analysis in previous studies [30-35], for any two samples in a biological system, when the Pg scale is Pg ≥ (61 ± 3)%, these two samples are similar to each other greatly and of the same inner quality. The similarities among these 29 samples were showed in Tables 3 and 4. In Tables 3 and 4, the same kind/class plants were showed in the same color area. From these tables, the similarities among the same kind plant samples were significantly higher than that among different kind plant samples. Common peak ratios among different kind plant samples are much less than Pg2 constant 61%.
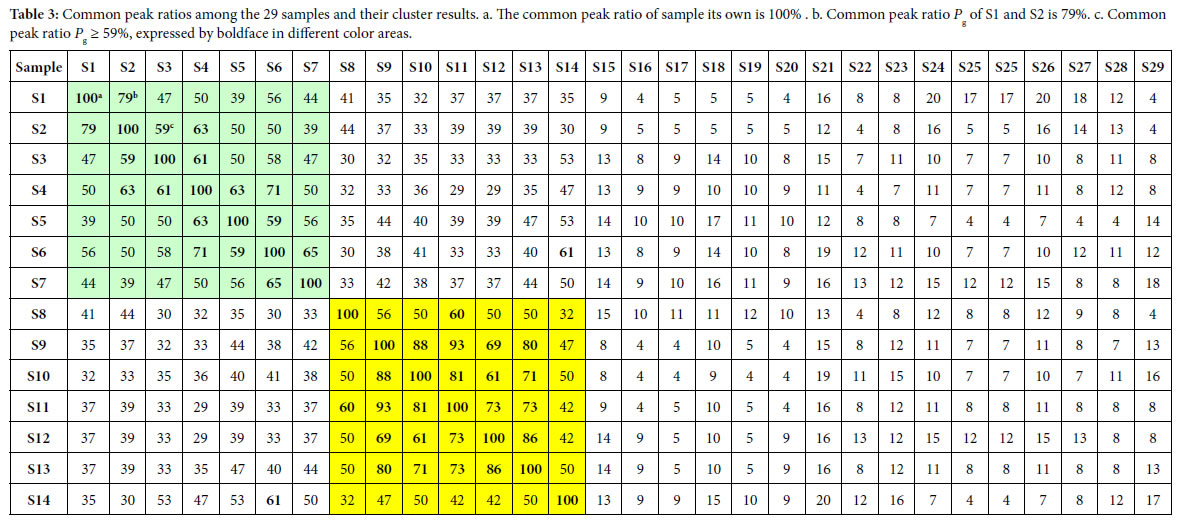
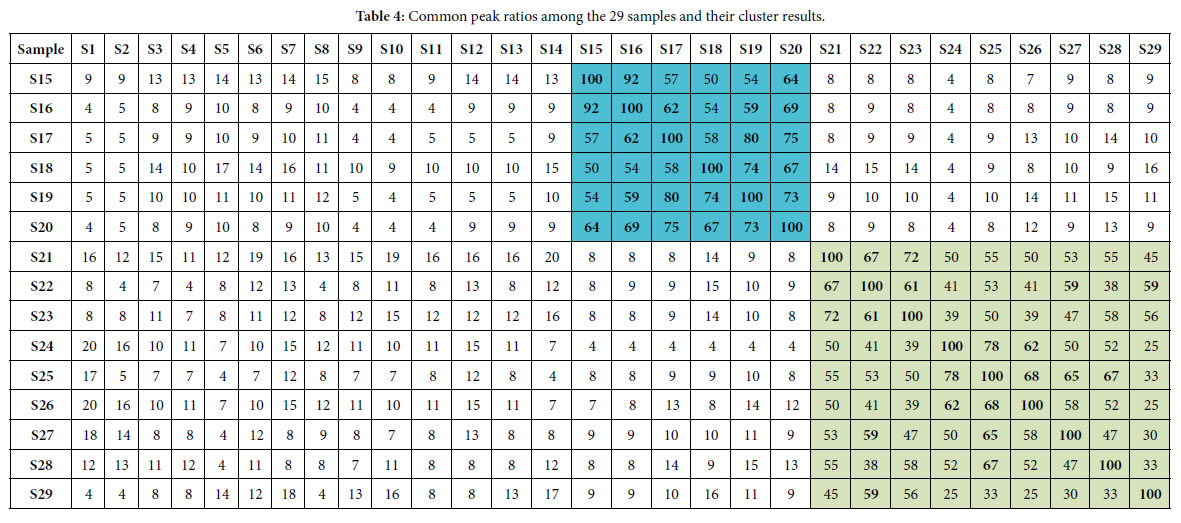
The definition of characteristic sequence:
For sample Si, its characteristic sequence is composed of these samples, whose common peak ratios related to Si fit to Pg scale Pg ≥ (61± 3)%. According to Tables 3 and 4, the characteristic sequences of 29 samples were obtained and displayed in Table 5. Their classification were performed based on their characteristic sequences.
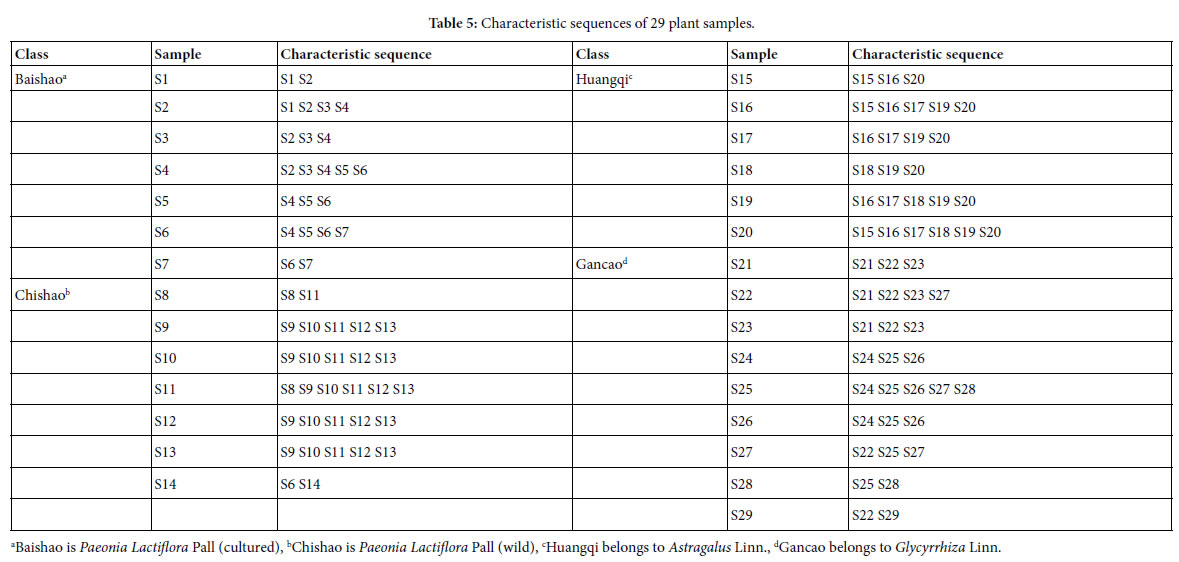
In accordance with the characteristic sequences of these 29 samples, the characteristic sequences in one class of samples were made up of themselves. Samples in one kind samples’ characteristic sequences form an independent sample set. There is no overlapped sample among different sample sets, expect for S14, whose characteristic sequence contains S6. In the 29 samples, 28 samples were classified correctly by means of their characteristic sequences. The correct ratio is 28/29 = 96.6%. Relying on the theoretical standard Pg scale Pg ≥ (61± 3)%, of the intrinsically taxonomic category, the four kind plants
Baishao S1-S7, Chishao S8-S13, Huangqi S15-S20, Gancao S21-S29, were accurately classified, or pattern recognized.
In particular, the significantly similar samples themselves in characteristic sequences are the best markers of their classes. This property is very important for classification, identification and pattern recognition of samples.
Summery, the similarities among Baishao and Chishao samples were much higher than that among any other two classes, such as Huangqi and Gancao samples, Baishao and Huangqi samples. It indicated that Baishao and Chishao samples should be close relatives.
These above results showed that similarity constant Pg2= 61% can be used as the quantitative standard to discriminate which plants are of the same efficiency, or used as the standard to determine the identical herbal medicines [30-32, 35].
On the other hand, suggesting m=4, that is there are four classes of plants, the theoretical standard Pg scale is Pg ≥ 53.2%, relying on the equation (13). To analyze the data in Tables 3 and 4, and get characteristic sequences of these samples. The results were very similar to that obtained by means of the standard Pg scale Pg ≥ (61 ± 3)%. There were trivial differences in their characteristic sequences. This also proved that generally biological heredity and variation information equation can represent intrinsic properties of biology exactly.
Analysis on close relatives among the four class plants
If these four kind plants are in the maximum variation state, that is at extreme radial variation state, accurate Pg scale Pg ≥ 24.4% (0.269=26.9%, according to equation (18)) could be obtained, when N=60, by equation (17). Pg scale Pg ≥ 24.4% is the theoretical boundary of close relatives of these 29 plant samples. Relying on this standard to determine characteristic sequences of these 29 samples, they could be classified into three classes perfectly, showed as follows.
Characteristic sequences of these 29 samples:
A class: Baishao and Chishao (Paeonia Lactiflora Pall)
S1:S1 S2 S3 S4 S5 S6 S7 S8 S9 S10 S11 S12 S13 S14a
S2:S1 S2 S3 S4 S5 S6 S7 S8 S9 S10 S11 S12 S13 S14
S3:S1 S2 S3 S4 S5 S6 S7 S8 S9 S10 S11 S12 S13 S14
S4:S1 S2 S3 S4 S5 S6 S7 S8 S9 S10 S11 S12 S13 S14
S5:S1 S2 S3 S4 S5 S6 S7 S8 S9 S10 S11 S12 S13 S14
S6:S1 S2 S3 S4 S5 S6 S7 S8 S9 S10 S11 S12 S13 S14
S7:S1 S2 S3 S4 S5 S6 S7 S8 S9 S10 S11 S12 S13 S14
S8:S1 S2 S3 S4 S5 S6 S7 S8 S9 S10 S11 S12 S13 S14
S9:S1 S2 S3 S4 S5 S6 S7 S8 S9 S10 S11 S12 S13 S14
S10:S1 S2 S3 S4 S5 S6 S7 S8 S9 S10 S11 S12 S13 S14
S11:S1 S2 S3 S4 S5 S6 S7 S8 S9 S10 S11 S12 S13 S14
S12:S1 S2 S3 S4 S5 S6 S7 S8 S9 S10 S11 S12 S13 S14
S13:S1 S2 S3 S4 S5 S6 S7 S8 S9 S10 S11 S12 S13 S14
S14:S1 S2 S3 S4 S5 S6 S7 S8 S9 S10 S11 S12 S13 S14
B class: Huangqi (Astragalus Linn.)
S15:S15 S16 S17 S18 S19 S20 S16:S15
S16 S17 S18 S19 S20 S17:S15 S16
S17 S18 S19 S20 S18:S15 S16 S17
S18 S19 S20 S19:S15 S16 S17 S18
S19 S20 S20:S15 S16 S17 S18 S19 S20
C class: Gancao (Glycyrrhiza Linn.)
S21: S21 S22 S23 S24 S25 S26 S27 S28 S29
S22: S21 S22 S23 S24 S25 S26 S27 S28 S29
S23: S21 S22 S23 S24 S25 S26 S27 S28 S29
S24: S21 S22 S23 S24 S25 S26 S27 S28
S25: S21 S22 S23 S24 S25 S26 S27 S28 S29
S26: S21 S22 S23 S24 S25 S26 S27 S28
S27: S21 S22 S23 S24 S25 S26 S27 S28 S29
S28: S21 S22 S23 S24 S25 S26 S27 S28 S29
S29: S21 S22 S23 S25 S27 S28 S29
a. S1:S1 S2 S3 S4 S5 S6 S7 S8 S9 S10 S11 S12 S13 S14, represents the characteristic sequence of sample S1.
Other sequences are of the same meaning.
From their characteristic sequences showed in the above classification results, these four kind plants could be divided into three close relatives. A class: Baishao +Chishao (Paeonia Lactiflora Pall). B class: Huangqi (Astragalus Linn.), C class: Gancao (Glycyrrhiza Linn.). This conclusion comply with the empirical classification. While for the classification based on medical efficiency and the kind of herbal medicines, theoretical standard Pg scale Pg ≥ (61 ± 3)% is more reasonable, see Table 5.
These results also indicated that for species, genus, they could be also clustered excellently by means of the theoretical boundary function(17),(18). This theoretical boundary can tolerate larger randomness of similarity in the same species, genus and so on. This theoretical boundary also suits to express elemental characteristics of biological evolution. Especially, the results of theoretical classification and close relative analysis both represented that common peak ratio Pg2=61%, indeed reflect the intrinsic characteristics of biological systems. Based on classical taxonomy, Baishao and Chishao both belong to Paeonia L.(genus), the same species, Paeonia Lactiflora Pall. However, there are some differences between them. Baishao is the plant Paeonia Lactiflora Pall having been cultured by human for thousand years. But Chishao is wild PaeoniaLactiflora Pall. Moreover, there exist great differences in their medical efficiency between Baishao and Chishao. This indicates their chemical compositions vary obviously. According to pharmacopoeia of P.R.China [54], two kinds of Huangqi Astragalus membranaceus(Fisch.)Bge. and Astragalus membranaceus (Fisch.), all belong to Astragalus Linn.(genus), their medical efficiency are identical. Two kind gancao :Glycyrrhiza uralensis fisch and Glycyrrhiza inflata Batal, they all belong to genus Glycyrrhiza Linn.(genus). Their medical efficiency are very similar to each other. The classification results relying on the theoretical standard Pg2 scale Pg ≥ (61 ± 3)% proved these two kind Gancao were in the same class, so were the two kind Huangqi medicine plants.
Baishao and Chishao are viewed as the same species, but their chemical compositions and medical efficiency are all different from each other distinctly. Theoretically, they should belong to different species, depending on researches in this article.
Huangqi and Gancao belong to the same family Leguminosae, but different genus. Two kind Huangqi samples belong to two species, and the same genus. In terms of the theoretical standard Pg scale Pg ≥ (61 ± 3)%, Huangqi samples are in the same class. So are the Gancao samples. These indicated for Glycyrrhiza Linn. and Astragalus Linn., Pg scale Pg ≥ (61 ± 3)% may be their theoretical standard of genus as well as that of herbal medicines, which are of the identical efficiency.
Depending on the above analysis, we know plant evolution is of some universal laws. Two similarity constants Pg1, Pg2, sometimes are suitable to be the theoretical standards of biological species, some time they are suitable for the theoretical standard of genus. Thus an hypothesis that biological system can be classified into some intrinsically taxonomic categories based on the three intrinsically theoretical criteria, can be proposed. Contrast to traditional classification, or taxonomy, only relying on empirical knowledge, these approaches can not reach the accurate and unchangeable results.
Nowadays, an reasonable classification scheme should be that all biology are firstly classified into the three intrinsic grade patterns, then divided these samples into sub-patterns in terms of the classical taxonomy methods.
Results and Conclusion on Intrinsic Taxonomic Categories and Their Theoretical Criteria
In plant systematics, there is no quantitative classification criteria for species, genus, and family, and other biological ranks. The results of this article showed there are three theoretical criteria corresponding to three intrinsically taxonomic categories, which correspond to three typically biological Variation Models. For Pg scales, Pg ≥ (61 ± 3)%, Pg≥ (69 ± 3)%, they can be accepted as the theoretical standards for some species, some genus, or some families. For Pg ≥ 1 ln Nd, it may be used as the theoretical standard to discriminate close relatives, such as Genus, Family (familia), Order (Ordo), Class (Classis), Phylumo (Divisi), Kingdom (Regnum) for some plants. This indirectly indicated that for different biological systems, their evolution speed vary significantly.
Most interestingly, these criteria may be a strong tool to investigate some laws in biologically macro molecules, such as DNA, RNA and protein sequences.
The research results also showed generally biological heredity and variation information theory, which was constructed based on the physical chemistry action model of heredity and variation materials, was able to accurately describe some heredity and variation laws in biological system, and suitable for many material levels. On the other hand, how to accurately determine the close relative among different biological systems is a very fundamental science subject. A theoretical boundary function 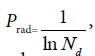 , or is precisely equal to
, or is precisely equal to 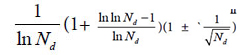 was derived from generally biological heredity and variation information equation. It can be used as a strong tool for determining close relatives.
was derived from generally biological heredity and variation information equation. It can be used as a strong tool for determining close relatives.
The laws or rules of material actions are usually more universal and more rigorous than that obtained by statistics. Through actions of substances, which produce differently biological phenomena, the strictly, scientifically and universally theoretical standards for classification should be established. This progress may promote biological science to some extent in the future, and open the door towards quantitative researches on intrinsically scientific principles of biology.
Acknowledgement
I sincerely thank academician WANG yongyan of Chinese Engineering Academy for his moral encouragement and support.
References
- Zhao-Hai L, Hong Q, Hong Z (2008) Statistical methods in genetics. Beijing: Science Press.
- Zhi-Fa Y (2011) Population genetics, evolution and entropy. Beijing: Science Press.
- Gang-biao X (2009) Plant population genetics. Beijing: Science Press.
- Mendel GJ (2012) Selected works of genetics. Beijing: Peking University Press.
- Robert P, John C DeFries, Gerald E McClean, Peter McGuffin (2008) Behavioral Genetics (Firth edition). Shanghai: East China Normal University Press.
- Francisco JA, Kiger JJ Jr (1987) Modern Genetics. Changsha: Hunan Science & Technology Press.
- Zhi-fa YUAN, Zhi-jie CHANG, Man-cai GUO, Shi-duo SUN (2015) Genetic analysis of quantitative traits. Beijing: Science Press.
- Clark MS (2007) Comparative genomics. Beijing: Science Press 110-136.
- Thomas HM (2007) The theory of the gene. Beijing: Peking University Press.
- Michael RB (2009) Bioinfomatics for geneticists: A bioinformatics primer for the analysis of genetic data. Beijing: Science Press.
- Dale JW, Von Schantz M (2004) From genes to genomes: concepts and applications of DNA technology. Beijing: Science Press.
- Campbell M, Heyer JL (2005) Discovering genomics,proteomics & bioinformatics. Beijing: Science Press.
- Licinio J, Wang ML (2006) Pharmacogenomics. Beijing: Science Press.
- Baldi P, Brunak S (2003) Bioinformatics: the Machine learing approach. Beijing: CITIC Press.
- Song-nian HU, Qing-zhong XUE (2004) Handbook of genomic data analysis. Hangzhou: Zhejiang University Press.
- Yang ZHONG, Liang Z, Qiong ZHAO (2001) An introduction to bioinformatics. Beijing: Higher Education Press.
- David WM (2006) Bioinformatics: sequence and genome analysis (second edition). Beijing: Science Press.
- Pevsner J (2006) Bioinformatics and functional genomics. Beijing: Chemical Industry Press.
- Jones NC, Pevzner PA (2007) An introduction to bioinformatics algorthms. Beijing: Chemical Industry press.
- David WM (2003) Bioinformatics: sequence and genome analysis. Beijing: Higher education press.
- Xian -yong WANG, Zheng-hua WANG (2011) An introduction to bioinformatics- the algorithms and applications facing to high performance computing. Beijing: Tsinghua University press.
- Yang Z (2008) Computational molecular evolution. Shanghai: Fudan University Press.
- Setubol J, Meidannis J (2004) Introduction to computational molecular biology. Beijing: Science Press.
- De-shuang HUANG (2009) The data mining methods of gene expression profile.Beijing: Science Press.
- Jun WANG, Li-juan CONG, Hong-kun Z (2008) Commomly used biological data analytical software. Beijing: Science Press.
- Nelson P (2016) Biological physics: energy, information, life. Shanghai: Shanghai Science & Technical Publishers.
- Rob Phillips, Jane Kondev, Julie Theriot (2012) Physical biology of the cell. Beijing: Science press.
- Park S Nobel (2010) Physicochemical and Environmental plant physiology (fourth edition). Beijing: Science Press.
- Plonsey R, Barr RC (1992) Bioelectricity- A Quantitative approach. Shanghai: Fudan University Press.
- Hua-bin Z (2009) Dual index information markedly similar sequence clustering analysis on IR fingerprint spectra of extracts of Guifu Dihuang and Jingui Shenqi pills with ethanol. China Journal of Chinese Materia Medica 34: 2325-2330. [crossref]
- Huabin Z (2015) A systematically theoretical distinguish approach for traditional Chinese medicine with identical quality. WorldChinese Medicine 10: 1078-1082.
- Huabin Z (2017) Two Chinese medicine species constants and the accurate identification of Chinese medicines. bioRxiv.
- Huabin Z (2018) Two biological constants for accurate classification and evolution pattern analysis of Subgen.strobus and subgen. Pinus. bioRxiv.
- Huabin Z (2018) A theoretical approach for discriminating accurately intrinsic pattern of biological systems and recognizing three kind soybean proteomes. bioRxiv.
- Huabin Z (2018) Accurate identification of varieties constants and multiple pairs between 2 Chinese medicine species. WorldChinese Medicine 13: 3158-3165.
- Huabin Z, Yuan J, Aiqin D, Linlin S (2005) Dual-index sequence analytical method for IR fingerprint spectra of the chloroform extract of Radix Glycyrrhizae.China. Journal of Chinese Materia Medica 30: 16-20. [crossref]
- Hua‐Bin Z, Yuan J, Ai‐qin D, Lin‐lin S, Hassan Y (2005) Dual-Index Sequence Analytical Method for IR Fingerprint Spectra of Ethanolic Extract of Various Gylcyrrhizae’s Root Species components. Analytical Letters 38: 1167-1178.
- De-Xin K, Shu-shi H, Rong-shao H, Xiu-li C, Yi-Bing W et al. (2010) Comparative study on the infrared fingerprint of Abrus Cantoniensis based on the methoods of sequential analysis of Dual-index and cluster analysis. Spectroscopy and Spectral Analysis 30: 45-49. [crossref]
- Hong L, Chang-ri H, Hong-xia L, Yuan-feng L, Meng-xiong HE (2008) Study on IR Fingerprint Spectra of Alpinia Oxyphylla Miq. Spectroscopy and Spectral Analysis 28: 2557-2560. [crossref]
- Hua-bin ZOU, Zhi-feng H, Hong ZHAI, Ying-qin WEI, Fei WANG (2007) The First and Second Cluster Analysis of Dual Index Grade Sequence of IR Fingerprint Spectra of Guifudihuang Pill and Jinkuishenqi Pill Samples and Their Quality Evaluation. Spectroscopy and Spectral Analysis 27: 2432-2436. [crossref]
- Hua-bin ZOU, Xin-1ing Z, Hong ZHAI, Ai-qin DU (2008) Dual index grade sequence pattern recognition of extracts with ethanol of Mingmu Dihuang pills and Zhibai Dihuang pills. ChinaJournalofChineseMateriaMedica33: 1543-1549. [crossref]
- Gurcharan Singh (2008) Plant systematics: An integrated approach. Beijing: Chemical Industry Press.
- Chang-Fa ZHOU (2009) Biological evolution and taxonomical principle. Beijing: Science Press.
- Han-Chen Z, Hao Z, Sheng-Li PAN (2009) Pharmaceutical botany (fifths edition).Beijing: People’s Medical Publishing House.
- Jin-wu WANG (2011) Spermatophyte taxonomy (second edition). Beijing: Higher Education Press.
- Simpson MG (2012) Plant systmatics (second edition). Beijing: Science Press.
- Hua-bin ZOU, Jiu-rong YUAN, Ai-qin D, Lin-lin S (2005) Dual-index sequence analytical method for IR fingerprint spectra of the chloroform extract of Radix Glycyrrhizae. China Journal of Chinese Materia Medica 30: 16-20. [crossref]
- Hua‐Bin Zou, Guo‐Sheng Yang, Zheng‐Ran Qin, Wen‐Qiang Jiang, Ai‐Qin Du et al. (2005) Progress in quality control of herbal medicine with IR fingerprint spectra. Analytical Letters 38: 1457-1475.
- Tao-tao PANG, Li-ming DU (2007) Common and Variant Peak Ratios in IR Fingerprint of Ilex Kudingcha with Duel-Index Sequence Analysis. Spectroscopy and Spectral Analysis 27: 486-489. [crossref]
- Hua-bin Zou, Jiu-rong Y, Aiqin D, Lin-lin S, Hassan YA (2005) Dual-Index Sequence Analytical Method for IR Fingerprint Spectra of Ethanolic Extract of Various Gylcyrrhizae’s Root Species components. Analytical Letters 38: 1167-1178.
- Kevin Yi-LY, Yung CS, Lim CS (2007) Infrared-based protocol for the identification and categorization of ginseng and its products. Food Research International 40: 643- 652.
- Hong-xia L, Su-qin S, Guang-hua LV, Kelvin KC Chan (2006) Study on Angelica and its different extracts by Fourier transform infrared spectroscopy and two-dimensional correlation IR spectroscopy. Spectrochimica Acta Part A 64: 321-326. [crossref]
- Huabin Zou, Jiurong Y, Wang Wei (2004) Theoretical identification of common peaks in fingerprint of Chinese medicine -a W- testing and discriminatory method. World Science and Technology/Modernization of Traditional Chinese Medicine and MateriaMedica 6: 50-56.
- Chinese Pharmacopoeia Commission (2005) Chinese pharmacopoeia 2005 edition (I)[S], Beijing: Chemical Industry Press.