Abstract
The paper presents a novel, cost-effective, data-driven, rapid and scalable way to deal with crises in any industry where the crisis is the result of easily swayed consumer opinion. We introduce here a system which allows anyone to understand the complexities of a problem by dimensionalizing the problem into four relevant questions, and four answers to each question. This dimensionalization is accomplished through an interactive ‘consulting chat’ which guides anyone through to the deeper understanding by the foregoing deconstruction. The deconstructed elements (answers to the questions), are combined into vignettes, combinations of the answers, presented to a small, cost-effective group of consumer respondents through the web, who rate the combination in terms an aspect deemed relevant (here, the feeling towards the food industry, either negative or positively, respectively). The results are automatically and immediately analyzed, to reveal the contribution of each of the 16 answers, sending the researcher a user-friendly, presentation-ready data in an Excel format. The presentation provides a full analysis of the data, showing the contribution of each answer both to the rating (cognitive), and to the response time to the vignette (non-conscious physiological measure). The presentation further shows the contributions of each answer to the ratings, first by total panel, then by gender, then age, and finally uncovers both two and three new ‘mind-set’ segments, possibly unknown previously, with these segments defined on the basis of patterns of responses to the 16 answers. The approach is illustrated by simple, easy-to-implement study on the controversial topic of the ‘food industry’s responsibilities in the obesity crisis.’
Introduction – lies and today
Proliferating media, and today’s increasingly simple ways to send messages, are mixed blessings. Certainly, information gets passed around. And, in the case of truly helpful information, an increasing number of people have an opportunity to get to that helpful information. The result is an increasingly interconnected world, with the blessing of communications that can be shared to help people.
Today’s communication environment is not, however, an unmixed blessing, as the topic of ‘fake news’ continues to reveal, day after day, local crisis after local crisis. An aphorism often attributed to the pundit and writer Mark Twain, but probably more likely originating with that arch cynic, Jonathan Swift, is ‘a lie can travel halfway around the world while the truth is putting on its shoes.’ In Swift’s original statement, more than three centuries ago, written in the Examiner of 1710.
Besides, as the vilest Writer has his Readers, so the greatest Liar has his Believers; and it often happens, that if a Lie be believ’d only for an Hour, it has done its Work, and there is no farther occasion for it. Falsehood flies, and the Truth comes limping after it; so that when Men come to be undeceiv’d, it is too late; the Jest is over, and the Tale has had its Effect…
(Wikipedia, https://quoteinvestigator.com/2014/07/13/truth/)
How does one combat lies, disinformation, or today’s popular phrase, Fake News? One cannot stop the issue at the source. Yet, it might be possible to fight using information derived from the mind of the citizen, uncovering just what messages are relevant, and just what messages are believable. That is, knowing the mind of the audience ahead of time or during the time of crisis may provide the necessary arms by which to defeat false information, not by power, but by enhanced, knowledge-driven persuasion.
Experiments instead of opinions
The thesis of this paper is that professionals in an industry can prepare for the often-unexpected onslaughts of bad news, fake news, and outright lies by doing their homework ahead of time. The homework begins by identifying the topics which could become the center of controversy. When the time is appropriate, and the situation warrant, all that is needed is an iterative set of small, affordable, focused ‘experiments’, studies on the response to messaging. The messaging deals with the topic. The experiments produce solid knowledge, insights, but beyond the general insight, specific phrases to use, and specific phrases to avoid.
The goal of the experiments is to identify simply ‘what really works’, what produces the ‘right persuasion,’ not just nice to know facts. The approach presented here comes not from today, but from an aphorism of the great doctor, Louis Pasteur, who opined ‘chance favors the prepared mind.’ A modern corollary of this aphorism might be ‘Knowledge casts a light, cauterizing the ghosts of opinions which infect the shadows.’ (Source author HRM)
The notion of being prepared for negative situations is not a new one. It lies at the heart of every expertise. “Practice makes perfect” and other aphorisms, or perhaps platitudes, too numerous to count, are taken as truth, and they are. What is new in this paper is the use of experimental designs of ideas, to ‘dimensionalize’ issues and situations, identify problems, and identify different statements and counterstatements that could be made, all within an empirical, defensible, cost-effective framework. The notion is iterative experiments as tactics, not experiments as sources of grand knowledge. In other words, experiments to answer the issues of the ‘here and now’, in the same frame, ‘here and now.’
The origin of the ideas comes from two sources. In the mid 1990’s, author Jeffrey Ewald began to work with IdeaMap®, the precursor of today’s Mind Genomics. An ‘Early Adopter,’ Ewald explored the use of systematic study of arguments and refutations, first in business with the objective of the client selling something, and then with the objective of the client having a ready-made set of tested communications to use in a crisis.
The second source was legal research done by author Moskowitz and colleagues, at the behest of author (Professor) James Wren of the Baylor State University School of Law. With several colleagues, including R Rex Parris, a noted trial lawyer, Wren encouraged Moskowitz to work with law cases, reducing them to message components, and then test combinations of these messages as arguments in a law case, in order to identify which argument drove the response of the jury in the desired direction. The efforts eventuated in a recently published book on Mind Genomics and the law [1]. Further, Parris has used the approach to win in law cases, including one substantial award of several hundred million dollars, which he attributed to this use of experimental design of ideas [2].
Demonstrating the approach in a vertical – the world of food
We all eat. To the average citizen, food is good, food companies are bad, news about food is available everywhere, often simply interesting content such as favorite flavors of the season or cooking shows with notable personalities. And then there is the not-so-good side. The food companies are under siege for presumably making us obese, for hooking us on salt, sugar, and fat, for destroying the quality of tomato, especially the tomato flavor for the tomato to last longer and shipper better.
The list is endless. The food industry has many issues to face, more coming almost each day. We have to eat. Food is, for the most part, perishable. Little animals and plants like to attack food, ruining it during their effort to survive by poaching on what should be the domain of human beings. And, since food is necessary, and is really for all living creatures, the adaptations we have made to get and consume food manifest themselves in a society where food plays many important roles, some of which are grist for the mill of social and health issues. And so, the never-ending, swirling controversies around food, new ones cropping up every day.
Introducing the steps
Our focus here is on affordable yet ‘industrial-grade’ production of knowledge about the mind of the citizen, specifically what messages convince the citizen about a topic, and what messages do not convince the citizen. It is vital that we create a system to generate the necessary information easily, rapidly, at a low cost, and in a format that can be used by industry sectors and their associated PR firms, not to mention professionals and students alike. Most important, however, is that the information be valid from a rigorous, scientific perspective, and that the approach must be, like Caesar’s wife, above reproach.
To accomplish our goals, we turn to the experimental design of ideas or messages, known by the rubric of Mind Genomics. Mind Genomics has been vetted by peer review in a variety of different areas [3]. The science of Mind Genomics furthermore traces back to well accepted methods in experimental psychology, specifically the pioneering work of the late R Duncan Luce in mathematical psychology [4], and in the ongoing work of Norman Anderson [5]. A Google Scholar® search of the terms ‘conjoint measurement’ and ‘conjoint analysis,’ will bring up many papers of a refereed nature, reaffirming the acceptance by both the academic and business communities.
At its inception, conjoint measurement was a labor-intensive approach. It would soon be simplified and expanded by Wharton Professor, the late Paul Green, in the 1970’s through the late 1990’s [6, 7]. The vision of creating a fast system, self-authoring, inexpensive, and powerful, was introduced by Moskowitz and colleagues at the start of the 21st Century, and the rapid adoption of the Internet [8].
The actual steps have been developed to fit into the form of a smartphone APP, a symbol of today’s focus on fast, easy, connection, and democratic. Thus, as we go through the first example (with results) in detail, the reader will be able to see how the thinking behind the problem immediately transfers into steps that one follows to bring the project to life. We illustrate the approach using an example from the issue of ‘obesity,’ motivated by the oft-heard canard that somehow the food industry is causing obesity by its practices. The fact that obesity is increasing, is clear from statistics, and well-accepted. That is a ‘fact on the ground’. What is not true, however, is the canard. How then do we fight it with a strategy and with knowledge and data from consumers?
Introducing the process and illustrating how it is tailored for everyday problems
Step 1 – Rethink the notion of the scientific ‘project,’ and look at the effort in service of an issue
We all eat. Many are fanatic in their pursuit of healthier lifestyles. As the world uses machinery, cutting down on the expenditure of calories, the natural course of people is to consume more than they need, leading to food-based problems, such as obesity. The food industry, people, orientations about lifestyle, and an increasingly contentious, better-informed, information-swamped, less critical thinking public all combine for a perfect storm. The storm, to mix metaphors, generates a lot of heat, controversy, sometimes light. And all too often a mentality of jousting, fighting, and perhaps most distressing, ‘grandstanding’ in the name of something, whether that something has value or not.
We deal with one topic in depth, obesity, showing what can be done in a matter of a few hours, at low cost. We show how the scientific process need not be long and ponderous, need not be a process which requires months and years of expertise, but rather can be a disciplined way to create the necessary knowledge. The rationale is that we want to show how very straightforward it is to run a relatively simple experiment (or several iterative experiments) in just a few hours per experiment, in order to prepare for onslaughts in the media, whether that is broadcast media, text media, or social media.
There is a subtext to the choice. We are writing this paper as a demonstration that almost anyone can use knowledge to properly address issues raised by adversaries, whether interviewers looking for sensationalism, or simply groups of people putting in potentially incorrect, even inflammatory material. Furthermore, we take our ‘own medicine,’ here, setting up a study easily (in 20 minutes), and running the study. We also show how the study can be set up as a ‘chat,’ further making the science available to those who don’t even need to realize that they are ‘doing science.’
We also show the type of information one can obtain from so-called convenience sample, small groups of individuals, easy-to-find on the internet, or to recruit using a so-called consumer panel supplier. We show that the knowledge obtained comes not from the proper sampling of people (confusing people with the ideas that they have), but rather from identifying clusters of ideas (mind-sets), using the people almost as simply the carriers of mind-sts. In other words, using the language and metaphor of genomics, we are interested in the mental genomes, not in the body which happens for the moment to be carrying the mental genomes.
Finally, we are not presenting the well thought out, magnificently produced set of brochures in the way well-established, richer corporations do. Rather, we are appealing to those in a cash-starved environment, with no resources, no magic ‘white knight’ riding in at the last minute to save the day.
Step 2 – Describe the tool which allows us to create knowledge quickly
The tool to be used is BimiLeap (www.BimiLeap.com). BimilLeap is a reduced version of a larger technology known as Mind Genomics. Mind Genomics, in turn, is a statistics-based research tool, used to conduct experiments in which respondents are presented with systematically varied vignettes (descriptions of ideas of situations), and rate the vignette on a defined scale [9].
Although this instantiation of Mind Genomics appears to be nothing more than a plain-vanilla survey, the reality is that the Mind Genomics interview is really an experiment. The respondent is presented with a set of systematically varied vignettes, the variation being the selection of what individual messages are combined in the vignette to create the totality. By systematically varying the composition of the vignettes, and having respondents rate each vignette as a single test concepts, the subsequent statistical analysis (regression analysis) reveals the contribution of every element or independent variable to the response.
The experiment design embodied in a Mind Genomics study dovetails well with the topics being explored above. The topic is made explicit and concrete by asking four relevant questions, which tell a story. The relevant questions, in turn, are answered by four separate statements for each question or a total of 16 answers or ‘elements.’ The selection of the topic, the four questions, and the four answers to each question remains in the purview of the researcher. Although one is forever plagued by the nay-sayer’s aphorism ‘garbage in, garbage out,’ the reality of the exercise is that one is forced to think. Not everything is garbage, and indeed, with practice, one learns to think critically, with the data upon repeated practice, suggesting ‘less garbage, more substance.’
Step 3 – Example: Addressing the contention that ‘The Food Industry Causes Obesity’
An instructive way to appreciate the approach instantiated by the APP is through a case history of an actual problem. The study that we discuss here was presented to a large audience at the Chicago 2018 Annual Meeting of the Institute of Food Technologists (IFT). The session topic was how to communicate as professionals.
The rationale for the topic came from the ongoing attacks faced by the food industry. The food industry is often accused as active participants in the growth of obesity world-wide. The rationale for such accusations ranges from anger at the R&D efforts which are believed to use any ingredients which make economic sense, to marketing which is accused in the sensationalist press of communicating misleading information to consumers. And then there are those who argue that there is, in some unwritten way, an implicit contract between the company and its consumers for the company to take an active role in the consumer’s health.
How then does the BimiLeap, work in such a situation, especially in the hands of novices, who do not have the resources of a corporation behind them, a corporation with trained lawyers, a well-paid public relations firm, an advertising (or several) advertising agencies, and a legion of consultants? What happens when the research effort to build the requisite knowledge must be accomplished, from start to finish, in two hours or less. How can this be done, with a reasonable number of respondents (30 or more), each participating in an experiment lasting 4-5 minutes?
Observation from dozens of different studies suggest that the selection of the topic is easy. What becomes difficult is the following set of steps, after the topic is introduced.
It is important to keep in mind that the study that we report was set up in less than ½ hour, was easy to implement on the web, could have taken as little as one hour to complete had we used an easy source of respondents rather than asking people to volunteer for free. The study, when completed, generated a full report Excel, within one minute of the end of the study. The Excel file was emailed to the researcher (author Zemel), within two minutes after the end of the study.
Step 1 – Set up the ‘contents’ of the study (Table 1, Figures 1-5).
The set up comprises selecting a name for the study (viz., the topic), creating four questions, and for each question providing four answers. Table 1 shows the questions as one might fully ask them. Figure 1 shows the way they are recorded in BimiLeap (www.BimiLeap.com).
Table 1: The four questions and their answers. The table shows the four questions in actual question format.
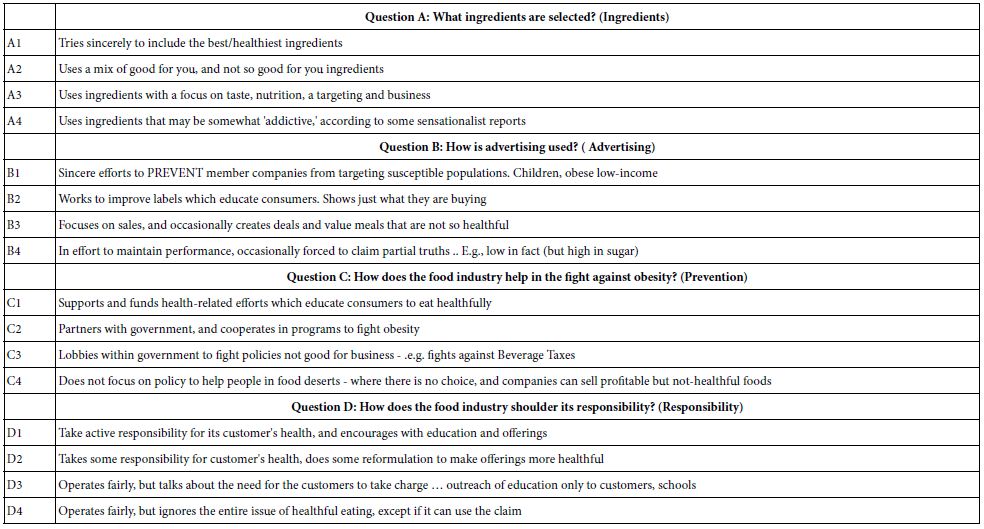
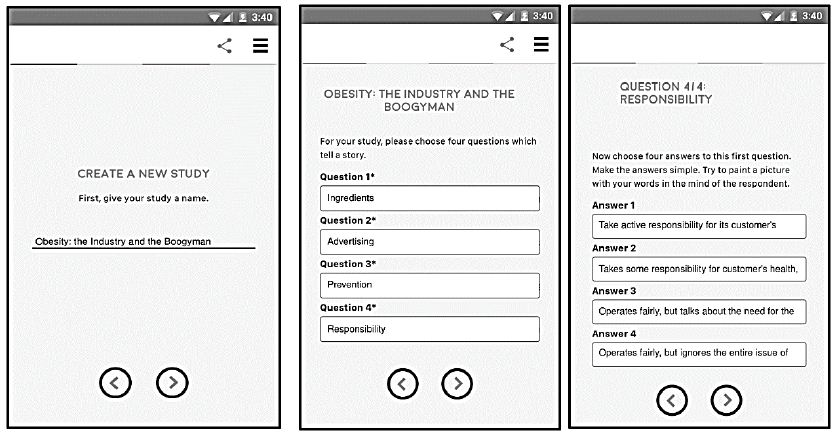
Figure 1: Define the name of the study, create four questions, and for each question provide four answers. The figure comes from the report, automatically generated at the end of the study, with all of the relevant set up slides captured as part of the research documentation.
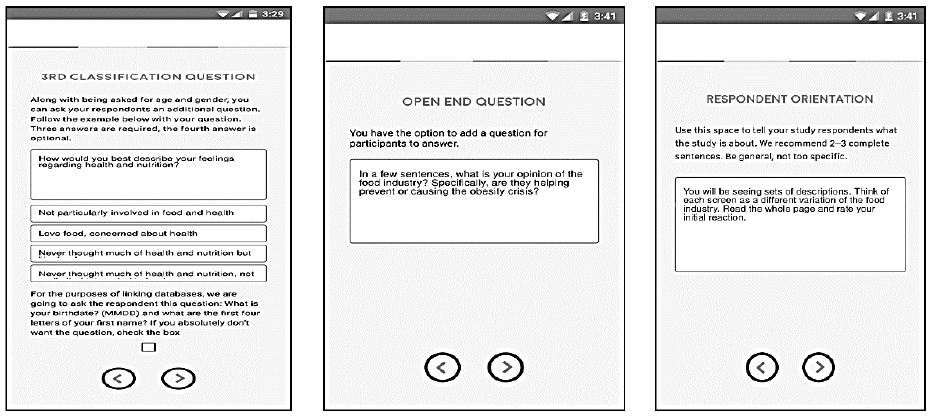
Figure 2: Create a third classification question (the first two are age, gender), create an open-ended question for the respondents to complete, and create an orientation page.
Figure 3: The rating scale (left panel). Final thoughts of the researcher (middle panel), and number of respondents desired for the study (right panel).
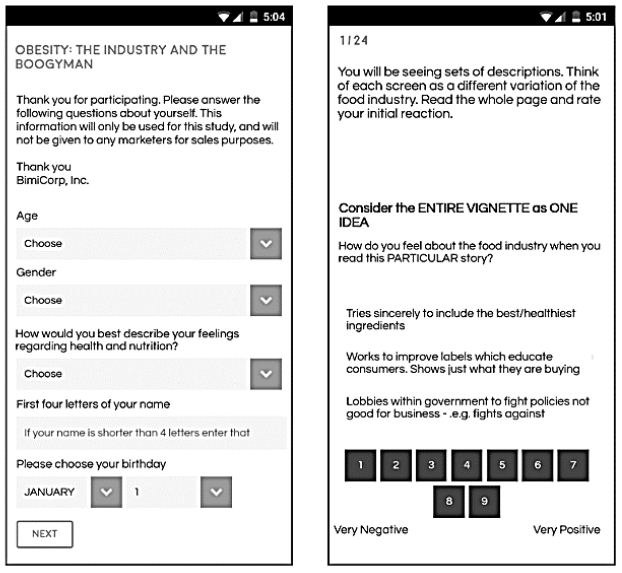
Figure 4: The respondent experience showing the classification question (left panel), and then one of the 24 vignettes shown as it would appear on a smartphone (right panel).
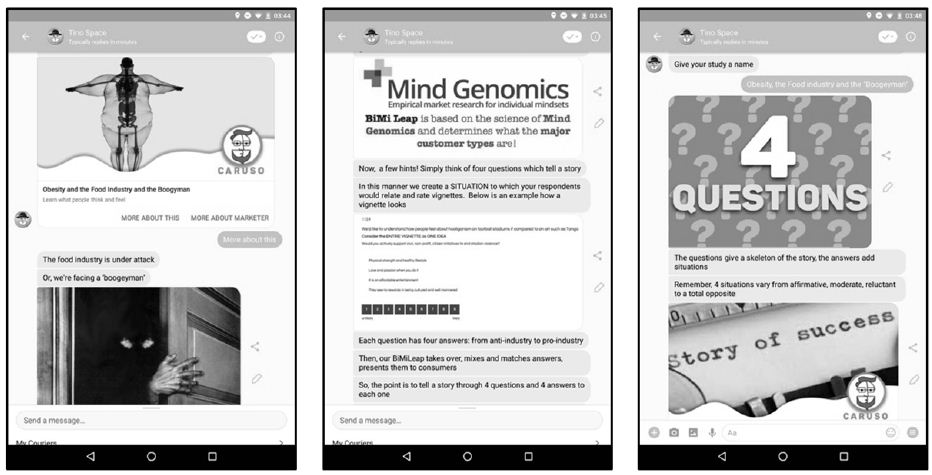
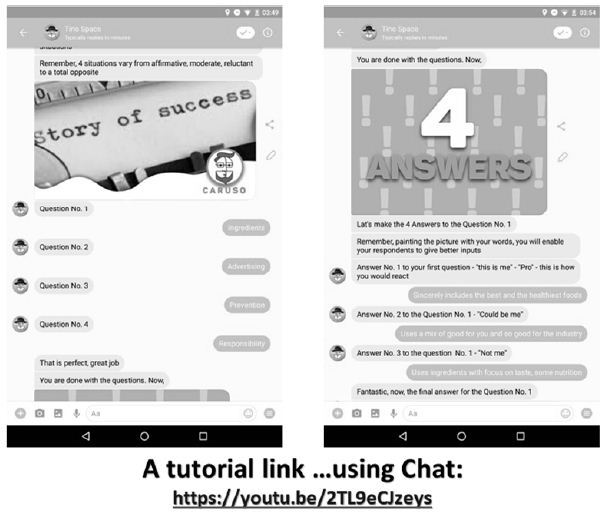
Figure 5 and 6: The Tino Space Chat. The figure shows the interchange between the researcher setting up the study and the chatbot. The objective is to make the set-up an interactive experience which simulates coaching.
It is as this stage that one is forced to think in a creative way. The selection of the topic, obesity and food, is straightforward. It is not hard to think of a topic, or even to refine our topic. The difficulty begins when it becomes time to ‘structure’ our inquiry, by asking four questions, and providing four answers to each question.
The first ‘stumbling block’ is the decreasing ability to think in a ‘systematic fashion’ We are not programmed in our education to think by asking a set of structured questions, although in reality that’s the easiest way to learn. A child asks questions. Despite the difficulties encountered by the researcher, it is vital that the researcher ‘stick with the script,’ and provide four questions. We simply require that the sequence of questions tell a story.
Figure 1 (middle panel) might have an actual question posted, such as ‘what is the advertising policy of the company?’ rather than just the word ‘advertising.’ Framing the question as a question versus framing the question as a simple statement makes no difference to the respondent, who will only see combinations of answers, and never the see the questions. The role of the questions is simply to facilitate the creation of answers.
From the point of view of science and education, it is becoming increasingly clear that we think easily in general terms, concepts, but have a hard time putting concrete ideas against those general terms. This step, questions, requires thought about STRUCTURE. We found formulating the four cogent question, to be modestly difficult for the researcher. Once the researcher formulates the four questions, a lot of the hard work has been done.
The four questions in Figure 1 are shown as one word each (ingredient advertising, prevention, responsibility, respectively.) The questions are short because they were selected by author Zemel, who had extensive previous experience. Instead of asking ‘what are the ingredients being discussed?’ Zemel simply put down the word ‘ingredients,’ knowing full well that the question is only used to generate the answers. The respondent never sees the underlying questions, but rather only sees the answers. The questions are selected to drive the production of the answers.
For each question, create four phrases which answer the question in different ways. The four answers pose a different challenge. Now, the task is not to think about structure, but rather to think about CONTENT. During the development of the BimiLep APP, it was first unclear how to generate this content. Putting the exercise into the form of question and answer made sense. The next issue was to determine the nature of the answers, how to make them readable, because it would be the answers, more correctly it would be the combinations of answers that would constitute the test stimuli.
The early efforts with BimiLeap ended up with researchers producing long-winded answers, complicated phrases involving different twists and turns of thinking. Others were simple one-word or two-word statements, i.e., very terse responses with little content. Neither type of ‘answer’ worked well. It became obvious that we need to specify how to write an answer. We came up with the suggestion that the answer be single-minded, and no longer than (approximately) 12 words. Formulating one’s thought in this structured manner called into play what might be called one’s ‘mental editor.’ No longer was the researcher grasping for structure in thinking, but rather now forced to provide answers selected with a focus on clarity of expression.
Advertising executives will recognize this step as one of the ways to create good ‘copy,’ i.e., good advertisements. Often, this creative step is described by the phrase ’problem-solution,’ namely pose a problem and then present a solution to that problem.
This step moves beyond the creation of a single, well-executed advertisement, or more correctly, a single, tested, vetted ‘concept,’ from which the advertising is to be created. Instead, the objective of this step is to create a bank of messages to be presented to the respondent in small, easy-to-read combinations. This first step, before creating the combinations, is to create the messages themselves, in a way which allows virtually ANYONE to do the basic creating. The question-answer format has been found by the authors to make the task easier. The question-answer format does not necessarily create brilliant ideas that will convince, but rather the format democratizes the process of coming up with material
Typically, consumer research studies using these approaches allow the researcher to ask many questions about who the respondent is, what the respondent believes, how the respondent has behaved with respect to the topic. The opportunity to acquire so much information about the respondent from the interview often ‘backfires,’ leading to data paralysis. The prevailing, typical attitude is ‘let’s not rush in and get the wrong information.’ Faced with the plethora of choice which potentially might produce analysis paralysis, the speed of the process is jettisoned in favor of ‘getting everything we can.’
BimiLeap was designed to be fast, modestly flexible, and inexpensive. The objective is to identify the ‘answers’, also known as element, which perform best, rather than acquire as much information about the respondent as possible. As of this writing (summer, 2021), BimiLeap acquires only three pieces of information about the respondent (age, gender, and a third question left to the researcher to select). The focus is clearly on the answers, the elements, not on the acquisition of extraneous information which ‘might somehow be useful.’
Figure 2 shows this third classification question. It is a sacrifice, of course, to leave information un-gathered, but it’s more important to have the study run quickly, and to recognize that deep knowledge will emerge when the researcher can do several of these small-scale studies, rapidly and affordably, building knowledge in a sequential, empirical, structured way. And, of course, create a library of responses to ideas, a library that can be searched easily to create even new constructs based upon the pattern of data from a set of somewhat related studies, dealing with one topic, or with a set of related topics.
Figure 1 shows how the app forces the researcher to ‘think through’ the issue by defining the topic, creating four questions, and then as an example, for the question regarding responsibility, provide four answers. BimiLeap forces the researcher into a structured way of thinking, beginning therefore with an undifferentiated issue, then a differentiation forced by the questions, and finally a further differentiation forced by the four answers to each question.
Once the questions are asked and the elements generated, the next steps create a rating scale (Figure 3, left panel), write instructions to have the researcher give some private, archival information about why the study and experiment were created (Figure 3, middle panel), and finally choose whether the study will be run free with data available to the world, or whether the study will be privatized, so that only the researcher knows the study and the data (see Figure 3, right panel).
Rating Scale: It is the rating question which allows the respondent to share his or her feelings. The objective of our project is to obtain a quick, almost intuitive response to the situation or the prospective client, which in this case is the world of food companies. A simple, rating question is:
Based upon what you just read (the vignette). Please rate your feeling on the scale below
1=Feel very negative about the food industry … 9=Feel very positive about the food industry
Privatization: The privatization option was created to make the approach attractive to researchers who wanted to keep their efforts private, yet still wanted to use BimiLeap to create the data. There are always several constituencies when it comes to research. Everyone would like the research to be free, and instantly available, such as source material from Google about all sorts of information, as well as so-called Big Data. No one necessarily realizes that data ‘cost.’ The plaint is that ‘after all, the data are out there and freely available. How can you charge me for what I can get for free?’ The foregoing plaint is very real, altogether too common, and destined to produce stillborn, meager results if followed. Privatization addresses the need to satisfy the constituency which wants to do the research for their own interests. The default position of BimiLeap is that the data are public, when not ‘privatized.
The policy of BimiLeap is to be free for anyone to use, with the stipulation that the study is ported to the web, and parts available for anyone to see. One can purchase the study results in their entirety for a nominal sum. If the researcher wants to keep the results entirely private, the researcher need only select the ‘privatize option.’
Experimental design, test vignettes, and the respondent experience
We are accustomed to survey research, which asks a question, gets one of several possible answers, and analyzes the frequency with which each answer is provided. The results of this exercise give us a sense of what the respondent thinks about a topic, when asked a single-focus question.
Our experience here was also instructive. Many of us who have come from traditional backgrounds in testing products, but also in testing concepts and advertisements, are accustomed to the conventional practice of presenting one test stimulus, after which the respondent rates that test stimulus on a dozen or more scales, or rating attributes. What happens when one has many stimuli, but only one rating scale? The reason for the many stimuli is obvious; it is in the pattern of responses to the stimuli where the real knowledge lies. And the reason for only one rating scale is that with 24 test vignettes and a limited time, with unwilling or uninterested respondents, it is better to have a short interview than a long one.
Mind Genomics and BimiLeap follow a different path because they emerge from the heritage of experimentation, not the heritage of surveys. The respondent is presented with a set of elements, in our case a set of answers to the questions. The questions do not appear. The task of the respondent is to inspect this seeming random combination of messages (viz.,, answers, elements), and assign a single rating to the combination. The task is a bit jarring at first, because the respondent tries to be ‘accurate,’ carefully reading each of the combinations, the so-called vignettes. The combinations comprise different types of information, often information which may be somewhat contradictory, and certainly not put together in the most felicitous prose. Nonetheless, the respondent’s task is to read the test combination, preferably quickly, and assign a ‘gut-level’ reaction, an unintellectualized response.
The effort to force respondents to evaluate these disparate combinations of answers, our test elements, often produces a nervous respondent. Some complain that they don’t want to participate in a study where the ‘test stimuli do not make sense.’ They drop out. The remainder, most participants from a paid research panel, do not drop out, and end up responding in the desired ‘gut-level’ or intuitive fashion.
The aforementioned experimental design dictates the 24 combinations of elements, with the property that the 24 combinations comprise 2-tuples of elements 3-tuples, and 4-tuples, so that each element (i.e. answer) appears equally often, and that no vignette ever comprises more than one answer from the same question The 16 elements, embedded in the 24 vignettes, are combined in a way which makes the 16 elements statistically independent of each other, permitting regression analysis to be performed on the ratings, to relate the rating to the presence/absence of each element.
Finally, each respondent evaluates a different set of vignettes. The underlying experimental design is the same, but the combinations, the structure of the vignette is such that each respondent evaluates a unique set of combinations. This is called a ‘permuted design’ [10, 11]. The permuted design allows the research to cover a wide array of possible combinations, so one need not know anything about the topic, and yet the experiment will quickly reveal the important versus the unimportant elements.
Before the respondent begins to evaluate the vignettes, it is important to tell the respondent a little bit about the study, but not much. The introduction is the orientation page which tells the respondent about the study. The orientation page should be short, to the point, without giving information which could lead the respondent to answer one way or another. The orientation simply tells the respondent the least amount of information. Figure 4 (right panel) shows the orientation, at the top of the screen, and a specific vignette, or combination of elements below, with the rating scale at the bottom.
In terms of the actual user experience, today’s panel participants have moved beyond paper and pencil, and have even moved beyond the traditional computer screen, and onto a smartphone. Smartphones are ubiquitous. In light of the use of smartphones as both communication devices by phone, and as browsers with which to text information and to traverse the net, we created BimiLeap so that it would perform well when the respondent was browsing on a smartphone. Indeed, in today’s world, it’s not even clear whether consumers have computers. It’s best to allow the interview to occur on a smartphone, on the screen. Figure 4 shows the respondent screens, set up for a smart phone.
Improving the set-up experience by means of Chat
initial experiences with BimiLeap suggested that the actual process would be fairly simple. That suggestion turned out to be more optimistic than was the case. The early uses of the APP were made by individuals with a great deal of experience in setting up studies for Mind Genomics. When others began to use the APP it soon became obvious that their experience was far less smooth than was thought at the start of the process. It became obvious that a novice researcher, doing the Mind Genomics process for the first time was facing a host of problems, most of which were more complex than frustrating than had been the case before.
The problems encountered by those setting up both the obesity study and others ranged from hard-to-understand instructions about what it means to ‘ask a question,’ to ‘provide an answer,’ and even to create rating scales and open-ended questions. Quite simply, what appeared simple to experienced researchers required ‘coaching,’ and perhaps even more.
Author Savicevic suggested that the process move in a direction made possible by a chat bot. We are all becoming increasingly with chats, which engage in a simulated conversation. The chat was designed by the staff at Savicevic company, Tino Space, to act as a more intuitive, chat-based acquisition. Figures 5 and 6 show the set-up process, this time by a chat. The chat set-up, now in refinement, appears to be a substantial improvement in the user experience, at least for the researcher who has to do the set-up work.
The researcher experience – automatically-analyzed results in presentation-ready format (Figures 7-8)

Figure 7: Full report in PowerPoint format.
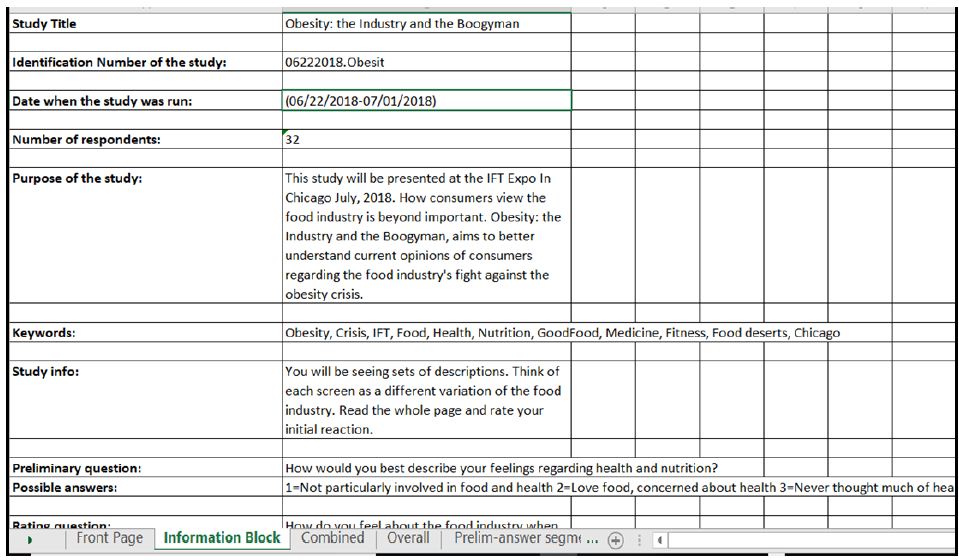
Figure 8: Information from the Excel file.
Today’s world operates on bites, small bits of information, presented in an entertaining fashion, or at least in a fashion which allows the information to be assimilated quickly. Rather than reading papers, even in areas which are very relevant, many people prefer to have the information presented in a manner that is exemplified by PowerPoint®. That is, rather than digesting the information for themselves from detailed text requiring thinking, many people prefer to have information ‘spoon-fed’ to them in a way which allows them to grasp the most important information.
In light of the emerging desire for fast, easy-to-understand information, called ‘the bottom-line’ or the ‘top-line,’ respectively, we have arranged BimiLeap to generate its own pair of reports, the first being a PowerPoint comprising all the relevant information (see Figure 7), and then an extensive, formatted Excel file with the relevant information, the summarized tables, and the raw data prepared for additional analysis (see Figure 8).
The report is a presentation-ready PowerPoint. The PowerPoint report is emailed to the researcher immediately after the close of the project, with the typical receipt of approximately one minute (by email). All the information in the report is either boilerplate or dynamically generated from the particular study being analyzed.
Accompanying the PowerPoint report is an excel file, also formatted, and presentation ready. The information page in Figure 8 is only one tab of a multi-tab Excel file, allowing the researcher to do further analysis of the data with other statistical analysis programs.
Part II – Explicating the resulting data – The food Industry and the issue of obesity
Illustrating how a study becomes one block in a scalable knowledge warehouse
An instructive way to appreciate the approach instantiated by the APP is through the data from our history. The study explicated here was presented to a large audience at the 2018 Annual Meeting of the Institute of Food Technologists (IFT), July 2018, in Chicago. The issue of the session was how to communicate as professionals.
The specific topic selected addresses the issue of combating ongoing negative press from activists and others who present their points of view in a variety of formats. The food industry is often accused as active participants in the growth of obesity world-wide. The rationale for such accusations ranges from anger at the R&D efforts which are believed to use any ingredients which make economic sense, to anger at marketing which is accused in the sensationalist press of communicating misleading information to consumers. And then there are those who argue that there is, in some unwritten way, an implicit contract between the company and its consumers for the company to take an active role in the consumer’s health.
How then does the, BimiLeap, work in such a situation, especially in the hands of novices, who do not have the resources of a corporation behind them, a corporation with trained lawyers, a well-paid public relations firm, an advertising (or several) advertising agencies, and a legion of consultants? What happens when the effort must be done expeditiously, to address a problem, and find the necessary messaging? The word ‘expeditiously’ means that there is relatively little time, perhaps a day or two at most, allowing perhaps one to six affordable, rapid iteration, each iteration totally complete, from start to finish in at most two hours. The challenge is to develop this approach, so that in 12 hours one can be fairly certain what to say and do, at least in terms of messaging.
This study, executed rapidly, shows what can be now done (2021), in as short a time as 1-2 hours, using a base of 30 respondents. A base of 100-200 respondents, easy to find on the Internet with online panel providers would take about the same time, approximately 1-2 hours at most. Note that the experiment from the point of view of the respondent takes about 4-5 minutes.
The foregoing sections have shown the set-up of this particular study on obesity and the perceived role of the food industry. We now move to the results, which emerged from the execution of the study with this small number of respondents. Just what emerged? And what conclusions can be made? The reader should keep in mind that the 32 respondents need not be the total number. There could be 132, or more respondents, just as easily. The question is really whether 32 respondents provide enough basic information, and whether one would be better off with the same study comprising 100 respondents, or say three studies, building upon each other, with say 32 respondents each. The answer to the foregoing question is not within the purview of this paper, other than to say that the opinion of the authors is that more studies, not more people for one study, provide a better strategy, assuming of course that there is a requisite minimum number of respondents for any one study.
Data analysis by building a model
The benefit of using the experimental design strategy emerges from the more powerful analytics which deconstruct the combinations, the vignettes, to the contribution of the individual elements, the messages or answers in Table 1. A paragraph is often more realistic than a single element, with the single element providing very little context. The respondent cannot ‘game’ the system, because too many different messages are present. This ‘blooming, buzzing confusion’ forces the respondent to assume a much less intellectualized role, and in turn to respond at almost a ‘gut level,’ the ‘System 1’ response so popular now in research thinking [12].
The actual ratings assigned by the respondent are transformed to a binary scale. The rationale for the binary scale, and thus the rationale for the transformation, is that managers and indeed almost everyone, more readily understands the meaning of a binary no/yes response, versus understanding the ‘meaning’ of a rating scale. Thus, when one is asked to rate ‘feeling about the food industry,’ the answers ‘feel positive’ versus ‘feel negative’ are easier to understand that the graded rating of ‘positive to ‘negative.’ We naturally gravitate to binary response, to no versus yes. For this study, ratings of 1-6 were transformed to 0, ratings of 7-9 were transformed to 100. Afterwards, the program added a very small random number to each transformed value, a value around 10-5. The random number ensures that the OLS (Ordinary Least-Squares) regression modeling incorporated in BimiLeap system does not ‘crash, when creating the model for the group, or the 32 individual respondent models, even when a respondent limits all the ratings of the 24 vignettes either to the low range of 1-6 (transformed to 0), to the high range (transformed to 100).
BimiLeap also measured the number of seconds from the moment that the test stimulus (combination of elements) appeared on the screen to the time that the response was made. BimiLeap then deconstructed the response time to the contributions of the individual elements, revealing what elements were processed more quickly (shorter response times), and what elements were processed more slowly (longer response times). The response time data warrants a totally separate paper by itself, and thus will not be reported here.
The experimental design and its permutations ensure that OLS regression can build an equation either for each person separately (individual-level model), and a model incorporating the data from many individuals, ranging from the total panel to a group incorporating, for example, only males versus only females (grand models). The specifics of experimental design and regression are well known and accepted in the academic and scientific communities [13].
At either the individual respondent level (so-called individual-level model), or at the group level (so-called grand model, BimiLeap computes the coefficient of a simple regression model, written as: Transformed Rating (Binary + random number) = k0 +k1(A1) …. k16D4). The small random number added to the transformed rating ensures that the OLS, ordinary least squares regression, will not crash, even though a particular respondent may have confined all 24 ratings to the range 1-6, or to the range 7-9. Confining the ratings to that range will result in all 24 cases for regression having the same value, 0 or 100, respectively. The small random number makes sure that such a situation will not a happen, for when that situation happens, the OLS regression ‘crashes.
Table 2, specifically the first set of numbers, shows the results from the total panel of 32 respondents. The data in Table 2 are sorted by the coefficient for the total panel. Despite what one might call a ‘thin sample,’ i.e., rather few people, even this small sample shows dramatic differences in the degree to which a specific element can drive a positive versus a negative feeling about the food industry.
Table 2: Parameters of the model relating the presence/absence of the elements to the binary variable ‘Feel positively about the food industry.’ Only positive coefficients are shown for the element.
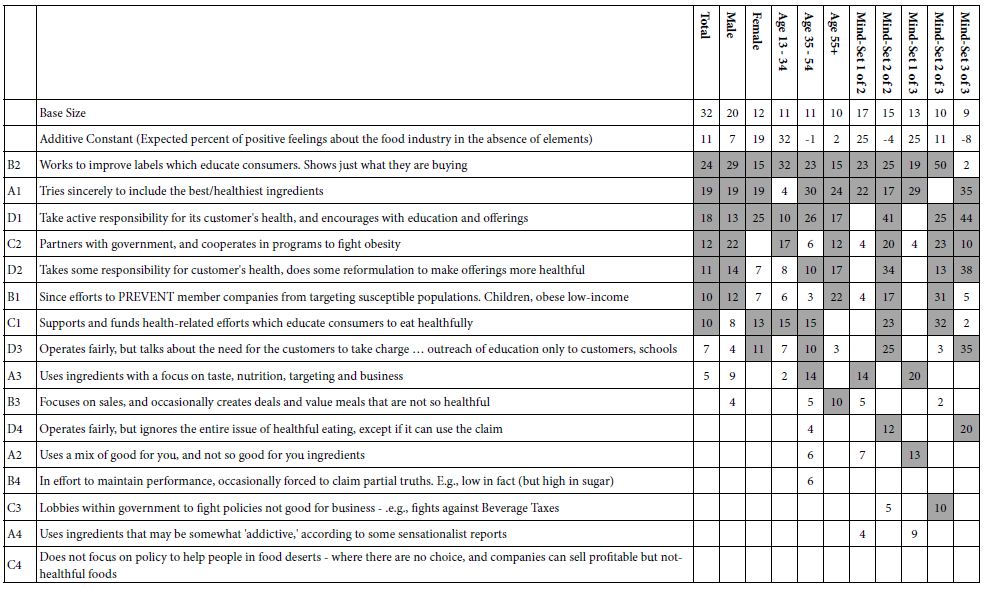
Table 2 shows the data from total panel, gender, age, and then mind-set segments, to be discussed in the next section. The specific data are not the focus, as much as the structure of the data, and what the data provide.
- The additive constant tells us the basic likelihood that in the absence of elements, the respondent will have a positive feeling towards the food industry (rating of 7-9 on a 9-point scale, in the absence of any elements). The additive constant is a purely estimate parameter from regression analysis but does have this meaning of a ‘baseline.’
- Each coefficient tells us the incremental percent of respondents who would be positive (rate the combination 7-9) if the specific phrase, the element or answer, were to be incorporated into the combination. The important coefficients are those 10 or higher. Conventional practice from thousands of these experiments suggests that coefficients around 8 or higher correspond to relevant, meaningful elements in terms of driving external behaviors. The cut-off is not ‘fixed in stone,’ however.
- Negative coefficients mean that when the element is incorporated into a combination, we would observe a reduction in the number of respondents who would assign a combination the rating of 7-9. The negative coefficients are not relevant to disclose the pattern and are not shown in Table 2. Rather, the cell is left blank.
- The practical implication here is that one rapid study provides a great deal of specific information need to make a corporation ‘smarter’ in its dealings. The aggregation of these studies creates a database with structured form, linking together the corporation, the topic, the response of different people, all in a coherent fashion with numbers that can be compared to each other.
- To summarize, the binary variable used as the dependent variable is created by transforming the ratings 7-9 to 100, and the ratings of 1-6 to 0. The rating 7-9 means that the respondent is pro-food industry when reading the vignette. The coefficients and the additive constant can be combined with the sum showing how likely it would be to obtain a rating of 7-9 when the respondent reads the combination comprising the elements whose coefficients are being additive.
Different mind-sets and the opportunity provided through targeted, effective messaging
During the past sixty years, since approximately 1960, marketers and then others have realized that the world does not comprise individuals who think alike. Whereas this statement seems obvious now, it was not always so, especially during the early part of the 20th century and before, when people were classified by ‘who they were,’ not by ‘what and how they thought.’ Marketers have successfully used the notion of ‘segmentation’ to divide consumers into groups, and have struggled, occasionally successfully, to message to these segments in the appropriate ways [14].
Dividing people into like-groups, segmentation, is often done at first by what people are, and by what they do, and occasionally by how they ‘think’ about a topic. With respect to our project here on the food industry and obesity, the researcher might divide the respondents by who they are (age, gender, body type, where they live, etc.), by what they do (e.g., the types of foods they say they eat, the types of restaurants they frequent, etc.), and by what they think (e.g., how do they respond to topics such as who is responsible for behavior, what is important – health vs pleasure, when it comes to food).
Segmentation of the above type, based on general measures about a person, may or may not help us understand the nature of what is important when it comes to communicating about the food industry and its role (or non-role) in the obesity epidemic. One would hope that dividing the population into traditional subgroups, based either on WHO A PERSON IS, or HOW A PERSON THINKS would reveal clearly different ways of thinking about a topic. Table 2 suggests that dividing people by gender or by age may show differences, not necessarily clear patterns which can form the basis of deeper knowledge and thus more effective actions in the world of messaging. Traditional ways of dividing people assume, without proof, that WHO a person IS determines WHAT a person THINKS. It may not be the case, and in general, it is not the case.
A better way to address the problem of mind-set segments comes from creating these segments from the materials closest to the topic. Beyond the conventional breakout of respondents into self-defined groups, BimiLeap performs a ‘k-means clustering’ [15] of the regression coefficients, first constructing two mind-set segments, then constructing three mind-set segments. These segments are called ‘mind-sets’ because they divide the respondents in the study by the pattern of the coefficients, i.e., by the pattern emerging when the respondent is confronted with a specific, targeted, defined, and quite limited situation.
In our case, we create or perhaps really discover underlying mind-set segments of a specific nature, relating to the issue of how one feels about the food industry, based upon the pattern of responses to the 16 messages. Since each respondent generated a set of 17 numbers (additive constant, 16 coefficients, one per answer), it is straightforward to cluster the respondents based on the pattern of the 16 coefficients.
For these data the k-means clustering, done on the 16 coefficients for the 32 respondents, suggested either two or three different clusters or mind-sets. Selecting the appropriate number of clusters is a subjective matter. The authors’ criteria are parsimony (fewer clusters are better), and interpretability (the clusters should tell a meaningful story).
The two-mind-set solution suggested one group interested in the food industry as a purveyor of ingredients, and the second group interested in the food industry as responsible for the well-being of its customers. Here are the strongest performing elements for the two-cluster solution, i.e., the solution which suggests two mind-sets.
For the purposes of this chapter, it is important to note that the performance of these elements is dramatic, +15 or higher, meaning that dividing people into mind-sets, viz., how they think, produces more knowledge and possibly better actions than simply dividing people by who they are. Such high coefficients almost never occur when these studies divide respondents by who they ARE, for the simple reason that a typical subgroup of individuals who LOOK SIMILAR from the outside often think in many different ways, ways, never be fathomed by simply knowing who a person IS.
Mind-Set 1 of 2 – Focuses on corporate moral responsibility to SELL better ingredients.
B2 Works to improve labels which educate consumers. Shows just what they are buying 23
A1 Tries sincerely to include the best/healthiest ingredients 22
Mind-Set 2 of 2 – Focuses on the corporate responsibility to EDUCATE consumers in healthy eating
D1 Take active responsibility for its customer’s health, and encourages with education and offerings 41
D2 Takes some responsibility for customer’s health, does some reformulation to make offerings more healthful 34
B2 Works to improve labels which educate consumers. Shows just what they are buying 25
D3 Operates fairly, but talks about the need for the customers to take charge.. outreach of education only to customers, schools 25
C1 Supports and funds health-related efforts which educate consumers to eat healthfully 23
The three-mind-set solution suggests that the original Mind-Set 2 of 2 (the food industry is ‘responsible to EDUCATE,’) really comprises two smaller groups, Mind-Set 2 of 3 feeling that the food industry is only partly responsible for the customer’s health/well-being for food, and Mind-Set 3 of 3feeling that the food industry and the customer are partners in the customer’s health-well-being.
Mind-Set 1 of 3 – Focuses on corporate moral responsibility to SELL better ingredients.
A1 Tries sincerely to include the best/healthiest ingredients 29
A3 Uses ingredients with a focus on taste, nutrition, targeting and business 20
B2 Works to improve labels which educate consumers. Shows just what they are buying 19
Mind-Set 2 of 3- Focuses on corporate moral responsibility to EDUCATE consumer.
B2 Works to improve labels which educate consumers. Shows just what they are buying 50
C1 Supports and funds health-related efforts which educate consumers to eat healthfully 32
B1 Since efforts to PREVENT member companies from targeting susceptible populations. Children, obese, low-income 31
D1 Take active responsibility for its customer’s health, and encourages with education and offerings 25
C2 Partners with government, and cooperates in programs to fight obesity 23
Mind-Set 3 of – Focuses on corporate moral responsibility to SELL better ingredients AND EDUCATE.
D1 Take active responsibility for its customer’s health, and encourages with education and offerings 44
D2 Takes some responsibility for customer’s health, does some reformulation to make offerings more healthful 38
D3 Operates fairly, but talks about the need for the customers to take charge … outreach of education only to customers, schools 35
The three-cluster solution may or may be useful. Certainly the two-cluster solution helps us a great deal to understand deep differences in the attitudes of the population. Cluster analysis, recall, is simply a heuristic to divide objects, here people, into homogeneous groups, homogeneity defined by mathematical criteria. It is the job of the research to choose the most parsimonious number of mind-sets. The goal is interpretability (the segments must be dramatically different in terms of that to which they respond), and parsimony (the ideal is as few mind-sets as possible.
We have focused on uncovering potentially new-to-the-world mind-sets, simply by running the Mind Genomics experiment. How, then, can the practitioner make use of this discovery? Before we finish up with the last topic, another new discovery, response times (engagement time), let us remain with the discovery of the two mind-sets. The PR strategist working for the food industry, or even a scientist interested in the minds of consumers, might wish to move beyond simply discovering the mind-sets. The practical application of the knowledge tells the food professional in the industry what to emphasize. But what should the professional say to a new person, a person not known beyond basic information about WHO and PURCHASE BEHAVIOR?
Recently, authors Moskowitz and Gere have created a system called the Personal Viewpoint Identifier, or PVI. The objective of the PVI is to create a small questionnaire, six questions long, the pattern of responses to which assign a person to the correct mind-set, with a probability substantially greater than change, although not perfect.
Figure 9 shows the PVI as seen by a respondent, after the PVI is set up. The actual PVI program can be accessed at www.PVI360.com. The research need only put in specified information emerging from the Mind Genomics study, information readily available from the Excel results (see Figure 8). Figure 9 shows three panels.
The left panel acquires relevant information about WHO the respondent IS
The middle panel allows the respondent to answer up to four relevant questions
The right panel presents the six questions in randomized order, these elements selected automatically by the PVI to maximize the chances of a correct assignment.
The PVI is sent out by link, the PVI is done by a person, and the feedback (mind-set membership, feedback information etc.) is sent both to the person and to a database under the researcher’s control. In this fashion, the mind-sets emerging from the study move from ‘nice to know’ facts to a way to optimize messaging to a given individual even immediately after the PVI have been completed.
Discussion & Conclusion
The project of science, and the process empowered by Mind Genomics and BimiLeap
Science, as commonly taught in schools, relies on the isolation and study of variables. There is an often- unstated belief and practice that careful, meticulous, painstaking work is the preferred approach to science. That which we know, according to such worldviews, must be obtained with care, and analyzed with precision. It may be acceptable in the everyday real world to do things ‘in the moment,’ but real science must be done with agonizing precision in order to be perceived as relevant and meaningful.
The research approach promoted in this article moves in a different direction. The notion is that with a reasonably powerful process to acquire knowledge and to understand the world, it may not be necessary to be as meticulous. In fact, the reality of the everyday is that we function quite well by grazing information, rather than sitting down to comprehend the information.
Corporate (and other) learning gained in short, easy-to-do, scalable arrays of studies
The most important outcome of this study is ‘what did we learn,’ and ‘was it worth the effort?’ We can answer those two questions easily. In additional to answering the question for the total panel we discovered new-to-the-world mind-sets with respect to an issue of obesity as a social issue linked with the food industry, Discovering mind-sets in the way we did it, with very few respondents (32), means that we are using the research to uncover sets of ideas which ‘travel together.’ We are not studying the entire world to discover these mind-sets, but rather using a convenience sample to discover the existence of the mind-sets. The distribution of such mind-sets in the population remains an issue to be addressed by larger-scale studies, powered by the PVI, the personal viewpoint identifier.
What is important to keep in mind is that we have established of mind-sets, done with a small sample of randomly chosen individuals, differentiating that discovery from the equal important but quite different question of these segments distribute in the population, another question that we can address, given a parallel piece of easy-to-use software.
There is a second outcome. That is the possibility learning a ‘lot more by simply doing a lot more.’ The evolution of science has been to increasingly larger, more expensive, more ponderous studies. That may be the case for the natural sciences and the physical sciences. As yet, it is not the case for applied science dealing with those topics where ‘the mind of man about external topics is king.’ Where topics can be broken up into aspects, dimensionalized, and studied with small, convenience samples, the Mind Genomics process will flourish, powered by BimiLeap and PV3I60.
Finally, anyone can become a researcher, not just those with advanced degrees, funding, and the permission of an IRB, Internal Review Board. We can envision an entire world of young and not so young researcher, in school, in companies, in play groups, all adding to the sum of knowledge through these experiments.
Envisioning one possible future of knowledge-building made possible by Mind Genomics
The efforts made in this study are, in actuality, quite simple, and the execution expedient. The objective of the effort was not to study the problem in detail, producing an archival document which investigates the problem from many different aspects. This latter approach characterizes much of today’s science, namely the attempt to define the parameters of the problem, and proffer a solution through experimentation, with one solution for one problem added to one solution to another problem, until the general issue is somewhat solved, or at least illuminated by the concatenation of these often-disparate solutions to a set of connected problems.
The approach presented here moves in a different direction, presenting the approach as a standardized method for create knowledge about a topic. There is already the ingoing assumption that the solution will not be perfect, that the range of the aspects studied will be limited, and that the data will be obtained through a small sample of respondents, not a large sample. We can liken this approach to an MRI of the mind, as the mind deals with various topics. Each study, comprising four questions, sixteen answers, perhaps 30-50 respondents, can be likened to one MRI photograph. The brain, or in our case, the mind, does not come into view and cannot be understood by one snapshot, one study alone. Rather, it is the buildup of the snapshots, the dozens, hundreds, thousands, tens of thousands of studies, and perhaps more, which begin to produce a general outline of what’s happening in the mind. Each snapshot alone is a minor effort, but the array of snapshots put together becomes the MRI of the mind, the picture of the mind, taken through this simple, scalable, affordable approach.
Acknowledgment
AG thanks the support of the Premium Postdoctoral Researcher Program
References
- Moskowitz H, Wren J, Papajorgji P (2020) Mind Genomics and the Law. 1st Edition. LAP LAMBERT Academic Publishing.
- Parris RR (2009 ) Jury Hands Down Stunning $370 Million Verdict Against Georges Marciano, GUESS? Inc Founder and Art Dealer, Announces R. Rex Parris. GES| 7/28/2009 5:21:29 PM LOS ANGELES, Jul 28, 2009 (Globe Newswire via COMTEX News Network).
- Moskowitz HR, Porretta S, Silcher M (2005) Concept Research in Food Product Design & Development. Ames, IA: Blackwell Publishing Professional.
- Luce RD, Tukey JW (1964) Simultaneous conjoint measurement: A new type of fundamental measurement. Journal of Mathematical Psychology 1: 1-27.
- Anderson NH (2001) Empirical Direction in Design and Analysis. Scientific Psychology Series. Routledge. Taylor & Francis Group New York.
- Green PE, Krieger AM (1991) Segmenting markets with conjoint measurement. Journal of Marketing 55: 20-31.
- Green PE, Srinivasan V (1990) Conjoint analysis in marketing: new developments with implications for research and practice. Journal of Marketing 54: 3-19.
- Moskowitz HR, Gofman A, Itty B, Katz R, Manchaiah M, et al. (2001) Rapid, inexpensive, actionable concept generation and optimization – the use and promise of self-authoring conjoint analysis for the foodservice industry. Foodservice Technology 1: 149-116.
- Moskowitz HR (2012) ‘Mind Genomics’: The experimental, inductive science of the ordinary, and its application to aspects of food and feeding. Physiology & behavior107: 606-613. [Crossref]
- Gofman A, Moskowitz HR (2010) Application of isomorphic permuted experimental designs in conjoint measurement. Journal of Sensory Studies 25: 127-145.
- Moskowitz HR, Gofman A (2004) System and method for performing conjoint measurement. Provisional patent application, 60/538,787, filed.
- Kahneman D (2011) Thinking, fast and slow. New York: Farrar, Straus and Giroux.
- Box GEP, Hunter J, Hunter S (1978) Statistics for Experimenters. New York, John Wiley.
- Claritas (1999) “PRIZM Cluster Snapshots: Getting to Know the 62 Clusters”.
- Jain AK, (2010) Data clustering: 50 years beyond K-means. Pattern recognition letters 31: 651-666.