Abstract
We present a new approach, Mind Genomics, to understanding the needs of prospective users with respect to a teaching APP designed to promote improved memorization of important texts. Using small-scale experiments, using the systematically varied messages in the form of stories or vignettes, Mind Genomics uncovers the customer-requirements of the APP. These vignettes are combinations of ideas about the product, its use, and the benefits to be obtained. The pattern of reactions to these vignettes reveals which specific features and benefits ‘drive interest.’ Mind Genomics does not require the respondent to intellectualize the need, an intellectualization which introduces response biases, and perhaps demand an answer that the respondent may not know. Rather, the deconstruction of the pattern of the immediate responses assigned almost automatically and without deep thinking, clearly reveals the underlying needs. The results from this small-scale study suggest three radically different mind-set segments. Mind Genomics, finds application where the respondent’s job is to make decisions, and where one would like to reduce the biases due to what the respondent expects the appropriate answer to be. We show how Mind Genomics can become an early-stage, rapid, affordable, and scalable system for deep understanding of human judgments.
Introduction
The Psychology of Memory and its Position in the 21st Century Information World
Studies of memory lie at the historical foundation of experimental psychology. Among the earliest reported publications is Hermann Ebbinghaus’ book on Uber die Gedachtnisse, Memory, reporting in detail his extensive work with memory drums and rote learning [1]. Memory and its association with learning has not lost its allure for researchers, and has become increasingly important once again, almost two centuries after Ebbinghaus excited a waiting world with his experiments. This new excitement does not deal with the academic studies of memory and the myriad effects of the stimulus and the person as influences. Rather, this new excitement about memory revolves around the realization that in this new world of instant information, critical thinking, not rote memory, is important
As technology continues to improve, educators focus increasingly on technological aids to education, called in some circles ‘Ed-Tech.’ Computers promise to accelerate the development of thinking. For some areas such as information retrieval, computers have now, at least in the minds of some people, supplanted human memory as a key for one’s learning. As if to say: One need not ‘remember’ anything. Google®, Google Scholar® and other technologies can store and recall more in a moment than a person could remember in a lifetime. Indeed, as this 21st century progresses, we see education in a maelstrom, as the new technologies conflict with old ways of learning.
One of the victims of this accelerated change in the way education is practiced comes from the loss of memorized information which comprised a person’s basic storehouse of knowledge. We no longer read very much, and our attention span is coming under suspicion as weakening. We are not disciplined in what we read, what we learn, since it is clear that computer-savvy young person, even as young as 8–10 years old, can extract enough information from web-sources that she or he can write a paper based on that “research”. Of course, their thinking won’t be as good as someone who has processed the information by thinking about it, but nonetheless the information will be there. Despite the plethora of information easily available, there is still the need for knowledge, memorized, processed, and incorporated into one’s mind, readily available for use in coping with the everyday [2, 3].
The foregoing is the negative part of today’s evolution, the loss of one’s store-house of information. Joshua Foer, who was the 2006 Memory Champion of the USA [4], co-founded a site, “Sefaria”, a storehouse of Jewish classic texts, searchable and clearly presented to any learner. When asked: “Why does anyone need to memorize nowadays, we have Google and Sefaria!”, Foer is said to have replied “Our memory is not like a passive bank account, in which the more you put into your account, the more you have to withdraw. Rather, our memory is like a lens, through which we see the world. What we remember actively guides our thinking, deepening our understanding. The more we remember – the better we think.” [5]
There is a positive part to the computer revolution as well. With the aid of machines, we can learn faster. Machines which provide feedback can become coaches, indeed tireless ones. A properly programmed machine can become a valuable ‘coach, when it can take the stimulus input, present it, acquires feedback on the subject’s reactions, and continue to do so, tireless, efficiently, hour after hour after hour.’
Psychology of Performance versus Psychology of Communication
Experimental psychologists are accustomed to studying processes, such as how we learn, the variables which drive the rate of learning and forgetting, and so forth. The focus of experimental psychology is on the person as a ‘machine, ’ with the goal to understand how this machine operates. The scientific literature of experimental psychology thus deals with well-contrived experiments, constructed to isolate, understand, and quantify aspects of behavior, such as learning and memory.
Less attention is given to what people ‘want’ in their lives. When we talk about a learning aid, we talk about what it does. The design of the machine, the so-called ‘customer requirements’ are left either to studies of human factors or studies of marketing, whether basic or applied. The discipline of Human factors studies the changes in behavior at the nexus of man-and-machine. Marketing studies what people want, with the goal of applying that knowledge to solve a specific, practical problem.
The study presented here incorporates aspects of experimental psychology, human factors, and marketing. The study here is an experiment, to explore how statements about features of a machine drive consumer’s responses. The experiment here was done in the spirit of human factors, to understand the aspects of the man-machine interaction. Additionally, the experiment was done in the spirit of marketing, to understand the types of mind-sets which may want different things, and the nature of the communications appealing to each mind-set.
Solving the Problem Using Experimental Design of Ideas (Mind Genomics)
Traditional methods to understand consumer requirements use a variety of different methods, ranging from an observation of what is being currently to (field observation), to focus groups which discuss needs, to questionnaires which require the respondent to identify what is important from a list of alternatives, and down to so-called A/B tests where the respondents experience alternative instantiations of a product, and the researcher observes which instantiation performs better, makes the changes, and commissions another A/B test.
Although a great deal of consumer research assumes that people ‘know’ what they want, the reality is that they do not. Kahneman & Egan [6] suggest that we operate with at least two systems of decision-making, the ‘Fast’ and the ‘Slow’, respectively, called ‘System 1’ and ‘System 2.’ In our regular lives we are presented with compound situations containing many different cues, situations to which we must respond quickly. We have no time to weigh alternatives in a considered fashion. The rate at which these compound situations come at us can be numbing when we stop to count them. Consider, for example, driving quickly, and the many decisions that must be made, especially when maneuvering in traffic.
The complexity of decision making, the involvement of Systems 1 and 2, respectively, in this emotionally tinged topic of learning to remember makes it imperative that we move away from simplistic methods of ‘asking people what they want, ’ and, instead, do an experiment in which what people want emerges from the pattern of responses, without any intellectualization on the part of the individual.
Mind Genomics eliminates the problems encountered with many of the approaches which require the respondent to intellectualize what may be impossible to intellectualize, much less to communicate. The objective of Mind Genomics is to identify the importance of alternative features of an offering by presenting many descriptions of the offering, instructing respondents to consider each description as a possible product, and then to rate the description. The respondent is not instructed to reveal the reasons for accepting or reject each specific alternative, but rather, almost in a non-analytical way, rapidly evaluate the offering quickly, almost automatically, as one does with small purchases. The pattern of reactions to the different offerings reveals what features of the offering are important, and what features are irrelevant, or even off-putting.
The Contribution of Experimental Design
The experiments in Mind Genomics are patterned after the way nature presents its complexity to us, but in a more structured format. Mind Genomics studies combine individual pieces of information, ‘messages’ or ‘ideas, ’ doing so by experimental design [7]. The combinations, vignettes, are presented to the respondent who is encouraged to make a decision, doing so rapidly, e.g., rate the vignette on an attribute. The experiment comprises the presentation of a set of these vignettes, here 24 in total, to each respondent, who reacts to the vignette, rates, and moves automatically to the next vignette, repeating the process. The experimental design, in turn, enables the researcher to deconstruct the rating into the contribution of the individual elements, the messages. To the respondent, the array of alternative vignettes evaluated in the space of five minutes or so might seem to be a numbing set of randomly combined ideas, but nothing can be further from the truth.
As will emerge from the analysis of responses to a description of a new APP, Shanen-Li, designed to help memory, consumer demands emerge quite clearly from the descriptions. Consumers are asked simply to be participants to evaluate ideas. They are not asked to be experts, nor even to proffer their opinion, but simply to give their immediate, so-called ‘gut’ reaction to each vignette or test combination.
The Mind Genomics Process – Setup
The first step in Mind Genomics asks four questions, and for each question, requires four simple answers, or a total of 16 questions. The questions are never presented to the respondent. Only the answers are presented in combinations, as we will see below. The questions provide a structure to generate the answers. It is the answers which provide the necessary information about the Shanen-Li APP.
A parenthetical note is appropriate here. When one begins the process of creating a Mind Genomics experiment, the notion of question and answer is easy to comprehend. The questions which, in sequence, tell a story, are themselves difficult to create, at least for the first two or three studies. The answers themselves are easy to create once the questions are formulated. Over time, and with repeated experience, the novice begins to think in this more orderly fashion of telling stories through questions and providing the substance of those stories through the answers. In a sense, the Mind Genomics process may somehow ‘train’ the user to think in a new, structured way, one which forces a discipline where there may not previously have been discipline.
One of the key features of Mind Genomics is that one need not know the ‘right answers’ at the start of the process, a requirement which is often the case for more conventional studies. Rather, Mind Genomics system is designed to be iterative, inexpensive, and rapid. That is, one can do a study in a matter of a few hours, identify the important messages or elements, discard the rest, and, in turn, incorporate new elements to the next iteration. Within the space of a day it is possible to do 3–4 iterations, and by the end of the four iterations one should have come upon the strongest messages. In this paper we present the first iteration in order to demonstrate the nature of the process and the type of learning which emerges.
Assembling the Raw Materials to Tell ‘Stories’
The first step in a Mind Genomics study consists of asking a set of questions which ‘tell a story.’ As noted above, this first step may seem easy, but it is not as simple as one might think. The objective is to summarize the nature of the stimulus through questions. Table 1 shows the four questions for the first study. These questions give a sense of a story. The rationale for these questions beyond ‘telling the story’ is to evoke answers, or elements, the messages containing the actual information which will appear in the test vignettes. The questions never appear in the study. They are only an aid to structure the vignette, and to stimulate the researcher to provide the meaningful elements which convey information, in this case information about the APP.
Table 1. The four questions and the four answers to each question.
|
Question A: What are the key pain factors with reading and recitation? |
|
|
A1 |
It is so frustrating and tedious to memorize texts |
|
A2 |
It is a pain to supervise someone memorizing texts |
|
A3 |
It is expensive to hire tutors to supervise students memorize texts |
|
A4 |
There is no way to plan and track progress |
|
Question B: What are the benefits of overcoming the pain? |
|
|
B1 |
Using an APP reduces the costs of educating a student |
|
B2 |
Students feels accomplished |
|
B3 |
The student experiences a sense of success, that turbocharges motivation |
|
B4 |
Self-directed learning, at student’s own pace increases motivation |
|
Question C: What are the key descriptions of how it works? |
|
|
C1 |
Use the APP to listen to any text at will |
|
C2 |
Recite the text and the APP checks for accuracy |
|
C3 |
The level of accuracy is reported, and the student is prompted to self-correct |
|
C4 |
The APP tracks progress and sends reports to parents and teachers |
|
Question D: What are the wow factors? |
|
|
D1 |
Students become masters faster than they can imagine |
|
D2 |
Students can’t put it down ‘til they get it right |
|
D3 |
Now there is a plan to succeed |
|
D4 |
The student can see their accomplishments and are motivated to keep going |
Each question, in turn, requires four answers to the question. As Table 1 shows, the questions are simple, and the answers are equally simple. Every effort is made to avoid conditional statements, and statements which require a great deal of thinking. Furthermore, the answers are phrased in every-day language, in words that a person might use to describe the APP or the experience of memorization.
When doing these types of studies, one often feels ‘lost’ at the start of the process. Our educational system is not set up to promote critical thinking of a Socratic nature, the type of thinking required by Mind Genomics. The notion of telling a story through questions is strange, as if the notion of providing alternative answers which may be ‘what is, ’ and ‘what could be.’ Nonetheless, with practice the exercise soon becomes easier, although it is not quite clear at this writing (2019) whether this Socratic approach can replace the traditional thinking, or whether the approach can be practiced more easily with repeated efforts.
Creating Stories by Experimental Design (Systematic Combinations)
People often respond based upon what they think the right answer either ‘IS’, or what they believe the appropriate answer to be. Questionnaire-based research is especially prone to mental editing, response biases, based on belief, or based on the covert, often un-sensed desire to please the interviewer. Computer-administered questionnaires may compensate for the latter, because there is no interviewer, but rather a machine. It may be difficult for the respondent even to respond to machines when the topic is emotionally tinged.
Mind Genomics moves in a different direction, using experiments to understand the mind of the respondent. In a Mind Genomics experiment, the respondent is presented with combinations of messages, one message atop the other, such as that shown in Figure 1. The respondent’s job is simply to rate the combination on a scale, without having to explain WHY the rating was assigned. It is hard at first for a respondent to evaluate this type of mix of messages because people have been taught to deconstruct compound stimuli, and then to evaluate each part of the compound stimulus. The notion of rating an artificially combined set of messages moving in different directions is at first strange, but then becomes very easy by the time the respondent rates the second or third vignette.

Figure 1. Example of a vignette and a rating scale for the APP.
Although the vignette in Figure 1 appears to have been designed by randomly throwing together different combinations, the truth is the opposite. The 24 vignettes for a respondent are carefully crafted so that the 16 elements, the independent variables, are statistical independent of each other, and that each element appears an equal number of times.
Table 2 shows schematics for the first eight vignettes for respondent #1. The vignettes are first presented in the original design format (top section), and then shown in a binary expansion (middle section). The regression program cannot work with the original design, expressed in terms of the questions and answers in each vignette. It is necessary to recode the design so that there are 16 independent variables, which, for any vignette, take on the value 0 when absent from the vignette, and take on the value 1 when present in the vignette.
Table 2. Part of the actual experimental design.. The table shows the first eight vignettes of 24 for the first respondent.
|
Test Order |
Vig1 |
Vig2 |
Vig3 |
Vig4 |
Vig5 |
Vig6 |
Vig7 |
Vig8 |
|
Question |
||||||||
|
A |
3 |
4 |
3 |
2 |
2 |
1 |
0 |
1 |
|
B |
3 |
3 |
1 |
3 |
4 |
2 |
1 |
0 |
|
C |
3 |
0 |
2 |
2 |
4 |
1 |
2 |
2 |
|
D |
2 |
4 |
1 |
0 |
1 |
0 |
2 |
2 |
|
Binary Transformation |
||||||||
|
A1 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
|
A2 |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
0 |
|
A3 |
1 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
|
A4 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
|
B1 |
0 |
0 |
1 |
0 |
0 |
0 |
1 |
0 |
|
B2 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
|
B3 |
1 |
1 |
0 |
1 |
0 |
0 |
0 |
0 |
|
B4 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
|
C1 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
|
C2 |
0 |
0 |
1 |
1 |
0 |
0 |
1 |
1 |
|
C3 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
|
C4 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
|
D1 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
0 |
|
D2 |
1 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
|
D3 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
|
D4 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
|
Rating |
1 |
9 |
1 |
9 |
1 |
9 |
1 |
9 |
|
Binary Transformation |
0 |
100 |
0 |
100 |
1 |
100 |
1 |
100 |
|
Response Time |
5 |
8 |
5 |
1 |
0 |
0 |
1 |
1 |
The bottom of Table 2 shows the two ratings and the response time. The first rating is the number on the anchored 9-point scale. The second number is the transformed rating. The transformation is done so that ratings of 1–6 are transformed to 0 and ratings of 7–9 are transformed to 100. Afterwards, a very small random number (<10–5) is added to the binary transformed ratings to ensure that the OLS (ordinary least-squares) regression will work, no matter whether the respondent uses the entire 9-point scale, or limits the ratings to the low part of the range (1–6), or limits the ratings to the high part of the range (7–9), respectively The transformation makes it easy for researchers and managers to understand the meaning of the numbers. Researchers and managers want to learn whether a specific variable, in our case a message, drives the answer ‘no’ (not interested) or yes (interested).
Each of the respondents is assigned a different experimental design, created by permuting the elements [8] the same mathematical structure and robustness of design is maintained, but the specific combinations change. This strategy differs from the typical research approach which ‘replicates’ the same test stimuli across many respondents in order to obtain a ‘tighter’ estimate of the central tendency. With more respondents, the standard error drops, and the researcher can be more certain of the repeatability of the result. This statistical strength is achieved by repeating the experiment with a limited number of test stimuli, chosen to represent the wide range of alternative combinations. Mind Genomics works in a totally different way, covering a lot more of the space, albeit with fewer estimates of any single combination of elements, i.e., fewer replicates of the same vignette. Often there is only one estimate of the vignette. The rationale is that it is better to cover a wide range of alternative stimuli with ‘error’ than a narrow and perhaps unrepresentative range of stimulus with ‘precision.’
Individual Differences: Average Liking of the Vignette versus Average Response
Do individuals who like the ideas about the Shanen-Li APP respond any faster (or slower) than individuals who don’t like the ideas? In other words, is there a discernible pattern at the level of the individual respondent, so that those who like an idea (on average) respond faster or slower than those who don’t like an idea?
Figure 2 shows a plot of the average rating of liking (average binary response) versus the average number of seconds (average response time). Each filled circle corresponds to one of the 50 respondents. It is clear from Figure 2 that, at the level of the individual respondent, there is no clear relation between how much a person ‘likes’ an idea presented by the vignette and how rapidly the person responds to the vignette. Those who, on average, don’t like the idea of the APP respond quickly or respond slowly as those who, on average like the idea.
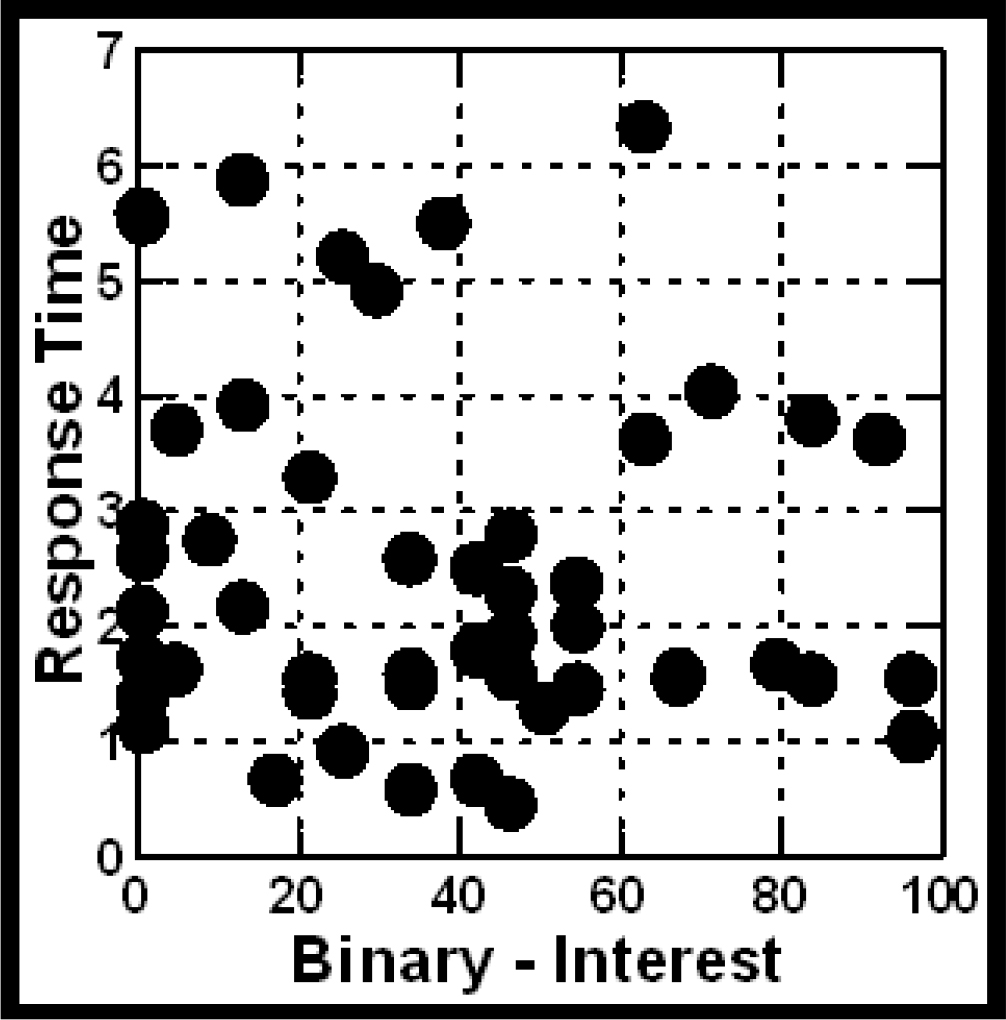
Figure 2. Relation between response time (ordinate) and liking of the idea (abscissa). Each filled circle corresponds to one respondent, whose ratings and response times, respectively, were averaged across the 24 vignettes.
Modeling
A deeper understanding of the dynamics of decision making emerges when we deconstruct the ratings (here the binary transformation) into the contribution of the individual elements. The experimental design ensures that the 16 elements are statistically independent of each other at the level of the individual respondent. Combining the data from the 50 experimental designs into one grand data set comprising 1200 observations, 24 for each of 50 respondents, allows us to run one grand analysis using OLS (ordinary least-squares) regression. OLS will deconstruct the data into the part-worth contribution of each of the 16 elements,
Table 3 shows the results of the first analysis, wherein the dependent variable is the binary transformed data (ratings of 1–6=0; ratings of 7–9=0), and wherein the independent variables are the 16 elements. The elements take on the value 1 when present in a vignette, and the value 0 when absent from a vignette.
Table 3. Coefficients of the model relating the presence/absence of the 16 elements to the binary transformed model for ‘like using this APP.’
|
|
|
Coeff |
T Stat |
P-Val |
|
Additive constant |
44.41 |
5.75 |
0.00 |
|
|
B3 |
The student experiences a sense of success, that turbocharges motivation |
1.66 |
0.35 |
0.73 |
|
C2 |
Recite the text and the APP checks for accuracy |
1.63 |
0.35 |
0.73 |
|
C4 |
The APP tracks progress and sends reports to parents and teachers |
1.61 |
0.34 |
0.73 |
|
A1 |
It is so frustrating and tedious to memorize texts |
1.50 |
0.32 |
0.75 |
|
A2 |
It is a pain to supervise someone memorizing texts |
-0.65 |
-0.14 |
0.89 |
|
B4 |
Self-directed learning, at my own pace increases motivation |
-1.34 |
-0.28 |
0.78 |
|
C3 |
The level of accuracy is reported, and the student is promoted to self-correct |
-1.88 |
-0.40 |
0.69 |
|
D4 |
The student can see their accomplishments and are motivated to keep going |
-1.88 |
-0.40 |
0.69 |
|
C1 |
Use the APP to listen to any text at will |
-2.07 |
-0.44 |
0.66 |
|
B2 |
Students feels accomplished |
-2.29 |
-0.48 |
0.63 |
|
B1 |
Using an APP reduces the costs of educating a student |
-2.71 |
-0.57 |
0.57 |
|
D2 |
Students can’t put it down til they get it right |
-3.42 |
-0.73 |
0.47 |
|
A3 |
It is expensive to hire tutors to supervise students memorize texts |
-3.47 |
-0.74 |
0.46 |
|
A4 |
No way to plan and track progress |
-3.51 |
-0.75 |
0.46 |
|
D3 |
Now there is a plan to succeed |
-5.21 |
-1.12 |
0.26 |
|
D1 |
Students become masters faster than they can imagine |
-5.60 |
-1.19 |
0.24 |
The equation estimated by OLS regression is expressed as: Binary Rating = k0 + k1(A1) + k2(A2) … k16(D4)
The additive constant is the expected percent of times that the binary value will be 100, in the absence of elements. All vignettes comprised at least two and at most four elements, so the additive constant is a purely estimated parameter. Nonetheless, the additive constant can be thought of as a ‘baseline’ value, namely the likelihood of a positive response towards the APP in general.
The additive constant is 44.41, meaning that in the absence of specific information; we are likely to see almost half the responses being strongly positive. The value 44.41 is a bit shy of 50. The T-statistics tells us the ratio of the additive constant to the standard error of the additive constant. The T-statistic can be thought of as a measure of signal to noise, of the value of the additive constant to the variability of the additive constant. The ratio is 5.71, quite high, with the probability of seeing such a high ratio being virtually 0 if the ‘true’ additive constant were really 0.
When we look at the individual elements for the total panel, we find that the coefficients are quite low, with the highest coefficient being 1.66. The coefficient tells us the expect increase or decrease in the percent of respondents who say that they would be interested in the APP if the element were to be included in the vignette. We begin with the additive constant (44.41) and add the individual coefficients of the elements.
What is remarkable is the low value of the coefficients for the total panel. The highest performing element is B3, ‘The student experiences a sense of success, that turbocharges motivation.’ The coefficient is only 1.66, i.e., about 2. The T statistic is 0.35, meaning that it’s quite likely that the real coefficient is 0.
There are some elements which, in fact, are negative, pushing respondents away.
Now there is a plan to succeed
Students become masters faster than they can imagine
Looking at Key Subgroups
We now move to an analysis of subgroups, specifically gender, age, and then mind-set segments. The respondent gender and age are obtained directly from the experiment. Respondents are instructed to give their gender (only male versus female), and to select the year of their birth.
For mind-set segments, we use the well-accepted method of cluster analysis [9] to discover complementary groups of respondents which respondent differently and meaningfully to the 16 elements. The experimental design allowed us to create an individual-level model relating the presence/absence of the elements to the binary-transformed ratings. Each respondent generates a unique pattern of 16 coefficients. We combine respondents into complementary groups with the property that the patterns of coefficients in a group (mind-set segment) are similar to each other, and differ from the average patterns for the other groups. The actual segmentation uses a measure of distance between respondents defined as (1-Pearson Correlation). When two patterns perfectly correlate (Pearson Correlation = 1), the distance is 0. When two patterns perfectly inversely correlate (Pearson Correlation = -1), the distance is 2.0.
Table 4 shows the additive constants and the strong performing elements for each defined subgroup. What should become immediately apparent is that:
Table 4. Strong performing elements by subgroups.
|
Total |
Males |
Females |
Age71–20 |
Age21–25 |
Age26+ |
Mind-Set C1 |
Mind-Set C2 |
Mind-Set C3 |
||
|
Base size |
50 |
23 |
27 |
25 |
19 |
6 |
12 |
22 |
16 |
|
|
|
Additive constant |
44 |
48 |
41 |
49 |
27 |
80 |
41 |
39 |
48 |
|
|
Gender |
|||||||||
|
|
Males |
|||||||||
|
|
Females |
|||||||||
|
A1 |
It is so frustrating and tedious to memorize texts |
2 |
-5 |
7 |
1 |
5 |
-12 |
-6 |
15 |
-10 |
|
|
Age |
|||||||||
|
|
Age17–20 |
|||||||||
|
|
Age21–25 |
|||||||||
|
C4 |
The APP tracks progress and sends reports to parents and teachers |
2 |
3 |
0 |
-5 |
9 |
14 |
19 |
-1 |
-6 |
|
A4 |
No way to plan and track progress |
-4 |
-12 |
4 |
-7 |
8 |
-29 |
2 |
4 |
-14 |
|
|
Age26+ |
|||||||||
|
C4 |
The APP tracks progress and sends reports to parents and teachers |
2 |
3 |
0 |
-5 |
9 |
14 |
19 |
-1 |
-6 |
|
|
Mind-Set Segments |
|||||||||
|
|
Mind-Set C1 -A tracking system with feedback |
|||||||||
|
C4 |
The APP tracks progress and sends reports to parents and teachers |
2 |
3 |
0 |
-5 |
9 |
14 |
19 |
-1 |
-6 |
|
C2 |
Recite the text and the APP checks for accuracy |
2 |
5 |
1 |
-2 |
6 |
3 |
12 |
-3 |
0 |
|
|
Mind-Set C2 – makes the memorization task easier for everyone concerned |
|||||||||
|
A1 |
It is so frustrating and tedious to memorize texts |
2 |
-5 |
7 |
1 |
5 |
-12 |
-6 |
15 |
-10 |
|
B2 |
Students feels accomplished |
-2 |
-8 |
3 |
3 |
-5 |
-13 |
-20 |
13 |
-9 |
|
B1 |
Using an APP reduces the costs of educating a student |
-3 |
-3 |
-2 |
5 |
-6 |
-23 |
-21 |
10 |
-6 |
|
A2 |
It is a pain to supervise someone memorizing texts |
-1 |
-2 |
0 |
3 |
2 |
-25 |
-4 |
9 |
-9 |
|
|
Mind-Set 3C – motivates the student through specific actions and results |
|
||||||||
|
|
Students can’t put it down til they get it right |
-3 |
-8 |
0 |
-4 |
0 |
-16 |
0 |
-14 |
13 |
|
D1 |
Students become masters faster than they can imagine |
-6 |
-9 |
-4 |
-5 |
-2 |
-17 |
-20 |
-11 |
12 |
|
D3 |
Now there is a plan to succeed |
-5 |
-9 |
-3 |
-7 |
1 |
-13 |
-5 |
-18 |
11 |
|
B3 |
The student experiences a sense of success, that turbocharges motivation |
2 |
6 |
-2 |
2 |
2 |
-2 |
-25 |
12 |
7 |
- The additive constant is modest, except for the respondents who are age 26+ (a small group). The respondents accept the ideas of a tutoring APP of this sort, but it will be the elements which must do the hard work.
- The strong-performing elements really occur among the mind-sets. That is, the opportunities do not lie among the respondents based on gender or age, but based on mind-sets.
- We do not know the mind-sets ahead of time. The mind-sets must be extracted through analysis of patterns, only after the experiment has been run.
- The key to success for this product is the array of mind-sets emerging from the segmentation. Even with the mind-sets, only a few elements drive interest, but when they do, they do strongly
- At the end of the paper, we present an approach to discover these mind-sets in the population.
The Speed of Comprehension and Decision Making
Before the respondent rates a vignette, we assume that the respondent has read and comprehended the material in the vignette. Although the responses occur very rapidly, suggesting very quickly reading and decision making, we can still uncover the relation, if any, between the element and the speed at which that element is comprehended. Figure 3 shows that many of the vignettes are responded to within a second or two.
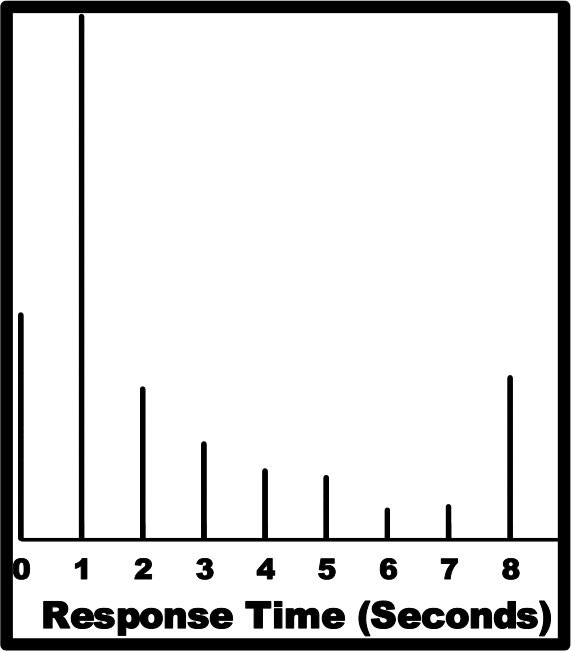
Figure 3. Distribution of response times for the 1200 vignettes. Response times of faster than 8 seconds were truncated to be 8 seconds, under the assumption that the respondent was otherwise engaged when participating in the experiment, at least when reading the vignette.
The response time it does not tell us much. We do not understand the dynamics of response time, specifically in this experiment, why some vignettes took longer times, some took shorter times. One way to discover the answer deconstructs the vignette into the contribution of the different elements to response time, in the same way that we deconstructed the contributions of the elements to the binary transform. The only difference is that we write the equation without an additive constant. The equation, written below, expresses the ingoing assumption that without elements in a vignette, the response time is essentially 0.
Table 5 presents the same type of table as presented by Table 3, namely a full statistical analysis of the elements, showing their coefficient, the t statistics (a measure of signal to noise), and the p value for the coefficient. The difference between Tables 3 and 5 is that for the binary rating, the model contains an additive constant because the ingoing assumption is that there is a predisposition towards the topic of a memory-training APP, but there is no predisposition in the case of response
Table 5. Coefficients of the model relating the presence/absence of the 16 elements to the binary transformed model for ‘response time.’ All response times of 8 seconds or more for vignette were transformed to 8 seconds.
|
|
Coefficient |
T Stat |
p-Value |
|
|
Elements responded to most slowly, i.e., ‘maintain attention’ |
||||
|
A4 |
No way to plan and track progress |
1.08 |
4.77 |
0.00 |
|
C3 |
The level of accuracy is reported, and the student is promoted to self-correct |
0.53 |
2.37 |
0.02 |
|
C4 |
The APP tracks progress and sends reports to parents and teachers |
0.53 |
2.35 |
0.02 |
|
C1 |
Use the APP to listen to any text at will |
0.61 |
2.72 |
0.01 |
|
D1 |
Students become masters faster than they can imagine |
0.61 |
2.70 |
0.01 |
|
A1 |
It is so frustrating and tedious to memorize texts |
0.65 |
2.89 |
0.00 |
|
C2 |
Recite the text and the APP checks for accuracy |
0.65 |
2.87 |
0.00 |
|
B4 |
Self-directed learning, at my own pace increases motivation |
0.70 |
3.14 |
0.00 |
|
A3 |
It is expensive to hire tutors to supervise students memorize texts |
0.74 |
3.25 |
0.00 |
|
B1 |
Using an APP reduces the costs of educating a student |
0.75 |
3.44 |
0.00 |
|
B2 |
Students feels accomplished |
0.75 |
3.41 |
0.00 |
|
D4 |
The student can see their accomplishments and are motivated to keep going |
0.80 |
3.54 |
0.00 |
|
A2 |
It is a pain to supervise someone memorizing texts |
0.81 |
3.59 |
0.00 |
|
B3 |
The student experiences a sense of success, that turbocharges motivation |
0.82 |
3.69 |
0.00 |
|
D2 |
Students can’t put it down til they get it right |
0.82 |
3.58 |
0.00 |
|
D3 |
Now there is a plan to succeed |
0.87 |
3.79 |
0.00 |
|
Elements responded to most quickly |
It is clear from Table 5 that most of the elements are reacted to quickly, as suggested by the coefficient, which is a measure of the number of seconds. The fastest elements are those which paint a word picture of an activity, and which may be visualized. The slowest elements are those which talk about less concrete topics, such as motivation and feelings.
Subgroups – Do They Respond at Different Speeds to the Elements
When looking at the deconstructed response times in Table 4 we see that virtually all response times range between one-half second and one second, respectively. There is no sense of any large differences between elements. A one-half second difference is still quite rapid. The story is quite different, however, when we look at subgroups defined by gender, by age, and then by mind-set segment. Table 6 shows those elements which catch the respondent’s attention, operationally defined as taking more than 1.15 seconds for the element to be ‘processed. Combining a high scoring element for interest with a high scoring element for response times means bringing together an interesting element which maintains the respondent’s attention during the stage of ‘grazing for information.’
Table 6. Elements showing slow response times, suggesting that they ‘catch’ the respondent’s attention.
|
Total |
Males |
Females |
Age17–20 |
Age21–25 |
Age26+ |
SegB1 |
SegB2 |
SegC1 |
SegC2 |
SegC3 |
||
|
A2 |
It is a pain to supervise someone memorizing texts |
0.8 |
1.0 |
0.6 |
0.8 |
0.9 |
0.4 |
0.7 |
0.9 |
-0.1 |
1.0 |
1.2 |
|
A3 |
It is expensive to hire tutors to supervise students memorize texts |
0.7 |
0.7 |
0.7 |
0.7 |
0.6 |
1.4 |
0.8 |
0.7 |
0.3 |
0.8 |
1.0 |
|
A4 |
No way to plan and track progress |
1.1 |
1.2 |
1.0 |
0.9 |
1.3 |
1.5 |
1.1 |
1.0 |
1.0 |
1.1 |
1.2 |
|
B1 |
Using an APP reduces the costs of educating a student |
0.8 |
0.6 |
0.9 |
0.6 |
1.2 |
-0.1 |
1.1 |
0.4 |
0.4 |
0.5 |
1.4 |
|
B3 |
The student experiences a sense of success, that turbo charges motivation |
0.8 |
0.8 |
0.9 |
0.4 |
1.3 |
0.9 |
0.9 |
0.7 |
0.8 |
0.8 |
0.9 |
|
B4 |
Self-directed learning, at my own pace increases motivation |
0.7 |
0.6 |
0.8 |
0.7 |
1.0 |
-0.1 |
1.0 |
0.5 |
0.7 |
0.4 |
1.2 |
Discovering the Mindsets in the Population
Mind-sets distribute through the population. The traditional approach to produce development and marketing often believed that ‘you will need or believe based upon WHO YOU ARE.’ The notion of ‘WHO YOU ARE’ may be a result of the person’s socio-economic situation or may be a result of a person’s general psychographic profile [10]. The premise of Mind Genomics is that people fall into different groups, Mind-Sets, not necessarily based on who they are, nor on what general things they believe. Table 7 shows that even for this small base of respondents, the three Mind-Sets distribute in almost similar ways across interests, gender, and age. A different method is needed to identify Mind-Sets emerging from these focused studies. It is unlikely that the Mind-Sets for this new-to-the-world division into Mind-Sets for this APP can be found in the analysis of so-called Big Data. A different method is need, the PVI, Personal Viewpoint Identifier, described below.
Table 7. Distribution of the 50 respondents in the three Mind-Sets, by interest for memorizing, by gender, and by age
|
Mind Set C1 |
Mind Set C2 |
Mind Set C3 |
Total |
|
|
Total |
12 |
22 |
16 |
50 |
|
Why are interested in memorizing |
||||
|
Songs |
6 |
12 |
12 |
30 |
|
History |
3 |
4 |
0 |
7 |
|
NA |
0 |
4 |
1 |
5 |
|
Quotes |
2 |
0 |
3 |
5 |
|
Lines |
1 |
2 |
0 |
3 |
|
Gender |
|
|
|
|
|
Male |
6 |
10 |
7 |
23 |
|
Female |
6 |
12 |
9 |
27 |
|
Age Group |
|
|
|
|
|
A17t25x |
4 |
12 |
9 |
25 |
|
A21to25x |
6 |
8 |
5 |
19 |
|
A26+ |
2 |
2 |
2 |
6 |
Conventional data mining is simply unlikely to identify Mind-Sets relevant to this specific topic of what appeals to a prospective buyer of this particular APP. The possibility, of course, is that through some ‘fluke’ there may be correlations between the nature of what people want in this APP and some information that is available about the person. The likelihood of the latter happening is virtually zero. Furthermore, even if the researcher finds an effective ‘predictor’ of mind-sets for this particular topic is no guarantee that the next particular topic will be as fortunate, leaving in its wake a variety of correlations. What is need is a system to assess, with some reduced error, the likely membership of an individual in a Mind-Set.
One way to create the system for assigning people to mind-sets consists of looking at the elements or answers which most strongly differentiate among the mind-sets. These elements can be structured as questions. The important thing is that they come from precisely the same source, at the same time, and with the same people which and who, in turn, defined the particular array of mind-sets. There is no need to match or balance samples. The pattern of responses points to the likely membership of a person in one of the three mind-sets.
Figure 4 presents the PVI, the personal viewpoint identifier, created specifically for this study. The left panel shows the questions. The right panel shows the three answer panels, which can go to the person, to the nurse, to the doctor, or become part of the person’s electronic health records, so that in the future the medical professional can know how to work with the patient to deal with the patient’s pain. The website as of this writing to ‘try’ this PVI is: http://162.243.165.37:3838/TT14/
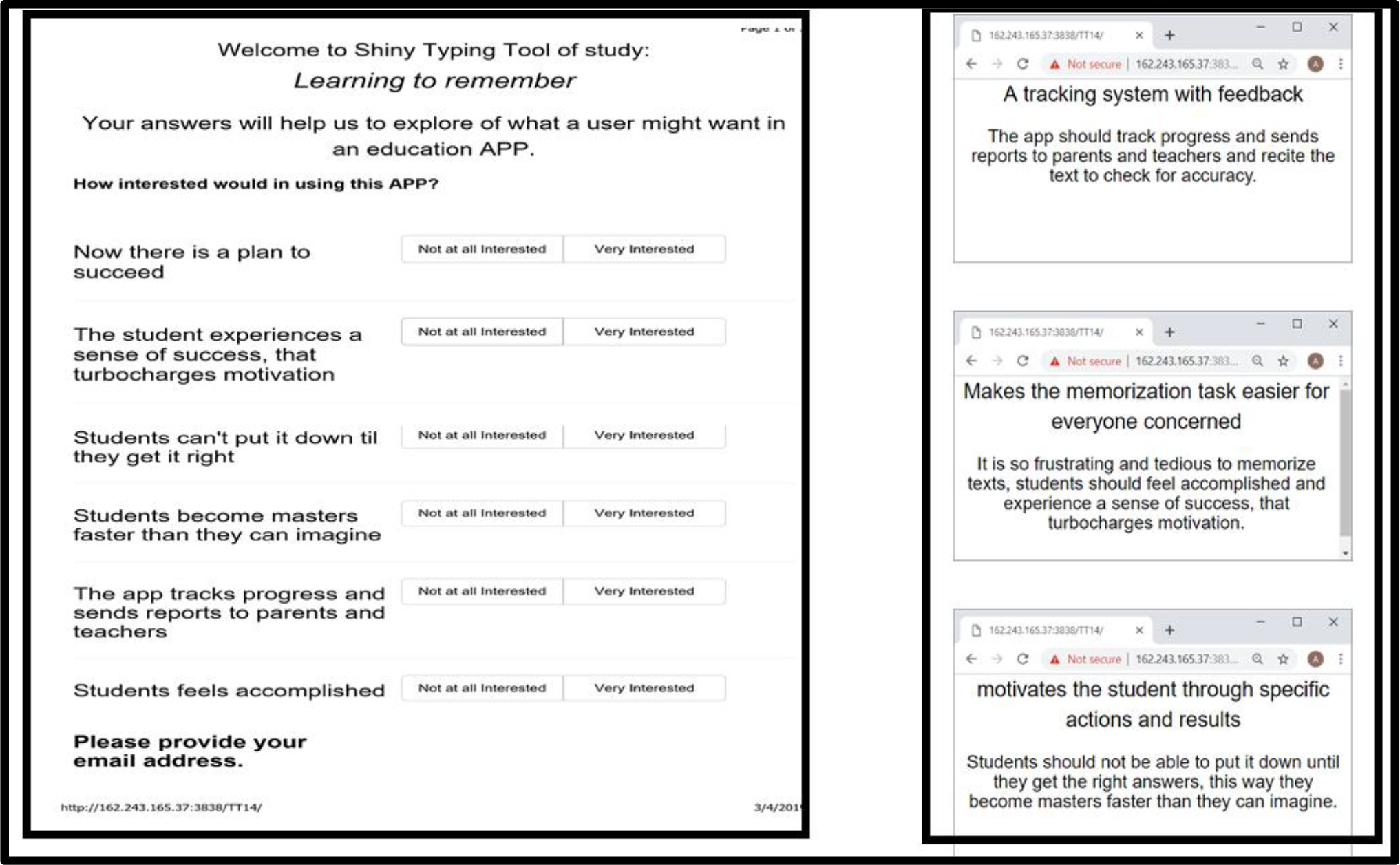
Figure 4. The PVI (personal viewpoint identifier) to assign a new person to one of the three mind-sets for the memorization APP.
Discussion and Conclusion
In the modern-day quest to introduce students to the new world of critical thinking, there is an increasing danger that we are going to eliminate the need for disciplined memorization. The notion that all the information one needs is ‘always available’ through a Google® or like system which is, in turn, ‘Always On’ produces the potential false sense that we need live only in the here and now as processors that which is immediate. There is no realization that we must create within ourselves a repository of knowledge, not just of unstructured experiences to which we respond, willy-nilly, as the spirit strikes.
The data from this exploratory study suggest that people are not aware of the need to memorize. When asked why they would want to memorize, 30 out of the 50 said ‘songs.’ It is clear that in today’s world, there may be a substantial loss of the value of remembering, even perhaps remembering history and literature, the essence of a cultured person. Our data suggest a severe problem developing in its early stages. We are becoming a culture of ‘just don’t know.’
Structured memorization and the increase in the human potential by combining this memorization to build a foundation of knowledge with the readily accessed corpus of knowledge which is ‘Always On’ may become the best of both worlds. Helping the student learn gives the student confidence. Helping the student think critically gives the student a capability. Helping the student create a bank of knowledge makes the student into a fully rounded individual who can reflect on what he or she knows, has learned. A person cannot be ‘cultured’ or ‘educated’ with knowing. Knowing means learning and retaining, memorizing. It is in that spirit that the Shanen-Li APP has been developed.
Acknowledgment
Attila Gere thanks the support of the Premium Postdoctoral Researcher Program of the Hungarian Academy of Sciences.
References
- Herrmann D, Chaffin R (2012) (eds.) Memory in historical perspective: The literature before Ebbinghaus. Springer Science & Business Media, 2012.
- Knowles MS, Holton E, Swanson R (1998) The adult learner: The definitive classic in adult education and human resource development (5th). Houston, TX: Gulf Publishing Company.
- Renshaw CE, Taylor HA (2000) The educational effectiveness of computer-based instruction. Computers & Geosciences 26: 677–682.
- Foer J (2019) https://en.wikipedia.org/wiki/Joshua_Foer .
- Foer J (2018) Personal communication with Rabbi E. Dordek, January 2018.
- Kahneman D, Egan P (2011) Thinking, fast and slow. New York: Farrar, Straus and Giroux.
- Leardi R (2009) Experimental design in chemistry: A tutorial. Anal Chim Acta 652: 161–172. [crossref]
- Gofman A, Moskowitz H (2010) Isomorphic permuted experimental designs and their application in conjoint analysis. Journal of Sensory Studies 25: 127–145.
- Steinley D (2006) K-means clustering: a half-century synthesis. British Journal of Mathematical and Statistical Psychology 59: 1–34.
- Wells WD (1975) Psychographics: A critical review. Journal of marketing research 12: 196–213.