DOI: 10.31038/PEP.2021233
Introduction
Worldwide, cancer is the second leading cause of death, with one of every six deaths caused by cancer [1]. There were 17 million new cases and 9.6 million cancer deaths worldwide in 2018, including approximately 1.7 million new U.S. cases and 600,000 U.S. cancer deaths [3]. The total financial cost of cancer in 2010 was estimated at 1.16 trillion U.S. dollars [1].
There have been significant reductions in cancer mortality, thanks to improved screening, early detection, and better treatment [1]. However, the worldwide incidence of cancer is expected to increase to 27.5 million per year by 2040 [28], a 62% increase from 2018. The U.S. expects an increase to over 1.9 million new cases per year by 2020, largely due to an aging Caucasian population and a growing African American population [5].
The World Health Organization states that “30-50% of all cancer cases are preventable. Prevention offers the most cost-effective long-term strategy for the control of cancer” [26]. Cancer can be prevented by reducing exposure to environmental risk factors, modifying lifestyle factors that are linked to cancers, and protecting against the effects of risk-factor exposures [26].
Tobacco is one of the most widely known and most modifiable risk factors for cancer and the process in determining this illustrates the value of the systematic study of cancer causes [15]. Lung cancer is the most common cancer in the world after skin cancer and the most deadly [24]. Before smoking became widespread, lung cancer was rare; however, as cigarette production and smoking increased, lung cancer became much more common. Smoking tobacco was found to be associated with lung cancer around the mid-20th century when a study showed that smokers were more likely to have cancer than non-smokers [15]. This relationship was confirmed by epidemiological and prospective studies, experiments, pathological observations, and chemical analyses [15]. Smoking was also found to be a risk factor for many other types of cancers and diseases, and tobacco is now understood to be associated with 33% of cancers and 22% of cancer-related deaths worldwide [28]. Cigarette smoking is associated with 80%-90% of lung cancer deaths in the U.S. [25]. Deaths caused by smoking cigarettes have an average latency of about 25 years; lung cancer deaths are expected to reach about 2 million per year during the 2020s or the 2030s [15].
As a result of the overwhelming evidence that smoking is a causal factor for cancer, there have been many anti-smoking initiatives. These efforts include preventing smoking initiation, helping smokers quit the habit, and reducing exposure to second-hand smoke [11]. Smoking cessation reduces cancer risk and can improve outcomes for cancer patients. Smoking cessation can reduce lung cancer risk by as much as 85% after 16 years of cessation compared to non-cessation [13]. Due to tobacco control measures that were implemented in the U.S. in the mid-1950s, about 32% (795,851) of the lung cancer deaths that would have occurred during 1975-2000 were prevented; the benefits of these measures will continue [11]. These huge reductions in deaths, suffering, and costs were possible because good epidemiological evidence uncovered the link between smoking and cancer.
Other cancer-prevention strategies that have grown out of accumulating epidemiological studies include reducing alcohol consumption [10], vaccinating against certain viruses [17], and improving diet and exercise [4]. The International Agency for Research on Cancer (IARC) determined that alcohol was carcinogenic after reviewing studies that showed an association between alcohol consumption and certain cancers [8]. One study involving eight European countries estimated that for 2008, 3% of cases in women and 10% of cases in men were due to alcohol consumption [20]. A U.S. study determined that 3.2% – 3.7% (18,200 to 21,300) of all cancer deaths in 2009 were attributable to alcohol consumption [12].
Many viruses have been shown to cause or be associated with certain cancers [17]. Individuals and health care providers can take preventive steps such as vaccinations, follow-up treatment to minimize the risk of developing cancer, and screening to maximize chances of early detection of cancer [17]. And because obesity, diet, and sedentariness have proven to be risk factors that are related and modifiable, individuals can make lifestyle changes to reduce their cancer risk while gaining other health benefits [4].
There have been improvements in cancer survival rates due to improvements in cancer detection and treatment, but the progress made applies to relatively few cancers [16]. Also, this does not spare patients the ordeal, financial cost, and disability of cancer treatment. Screening guidelines are available for very few cancer types, so many cancers are detected at later stages and, therefore, have a lower survival rate [9]. In addition, incidence rates of some of these poorly understood cancer types are increasing. Cancer prevention is the least costly and most desirable approach to combat the expected increase in cancer incidence [26]. However, to achieve this we need epidemiological research that focuses on identifying risk factors for poorly understood cancer types.
A traditional epidemiological approach, such as the “Cancer Prevention Studies” (CPS), requires a large enough study group, long follow-up, and is costly [7]. Therefore, this approach is limiting, especially for poorly understood cancers, which tend to be rarer cancers. In addition, the research landscape has changed significantly. Information technology was one of the most significant technological developments of the twentieth century and has affected every aspect of our lives. It has made us very interconnected to people, activities, and the environment. Determining any effect of these connections is difficult due to the complexity and numerosity. Fortunately, these technological developments have also made significant advances that can be applied to health research. We have, are generating, and are capturing more data about many different aspects of our lives than ever before. We need to use current technology and data to overcome the limitations of the traditional epidemiological approach. We must develop reliable, efficient, and cost-effective research methods to identify possibly risk factors for poorly understood cancers.
Purpose
Our main objective in this study was to identify cancer types that represent a health burden, but for which environmental and lifestyle risk factors are poorly understood (i.e., without an established causal risk factor). We used a combination of inclusion and exclusion criteria to identify these cancers. The inclusion criteria were cancer types 1) without screening guidelines; 2) with low survival rates; and 3) with increasing incidence. Cancer screening aims to detect cancer before the individual becomes symptomatic, and early detection usually results in more successful treatment and greater survival [27]. Currently, only four types of cancer – breast, cervical, colorectal, and lung – have broadly accepted screening recommendations [16]. The cancers with low survival rates tend to be cancers that are more difficult to detect and to treat. An upward trending cancer indicates a growing concern that should be investigated to identify risk factors and reduce incidence. The primary exclusion criterion was cancer types with established causal risk factors. By default, cancer types with screening guidelines, without low survival rates, and/or without increasing incidence were excluded.
Secondarily, we propose a new methodological approach to study the etiology of these rare cancers that maximizes data utilization without the need for costly epidemiological studies, such as the “Cancer Prevention Studies”. This design allows exploration of the relationships of selected cancer with various potential risk factors without the financial and feasibility barriers of traditional epidemiological designs.
Methods
We used data from the National Cancer Institute’s (NCI’s) Surveillance, Epidemiology, and End Results (SEER) Program. The SEER Program collects cancer incidence and survival data for every cancer case reported from population-based cancer registries covering approximately 34 percent of the U.S. population spanning 19 geographic areas. The program started in 1975 with nine registries and now collects data from twenty-one registries. Based on the broad coverage area, the data collected by the SEER Program is representative of the U.S. population [21].
SEER data are coded to ICD-O-3 and are grouped by major cancer site/histology [22]. The data have 102 groups in a hierarchical format, ranging from all sites to miscellaneous. SEER incidence data have both the rate (per 100,000 and age-adjusted to the 2000 U.S. population) and count. Survival data provide observed, expected, and relative rates. Incidence trend data show overall percent change, annual percent change (APC), and the rate for each year. For this study, we used incidence data for 2011 through 2016 and survival data for the five-year period 2011 to 2015.
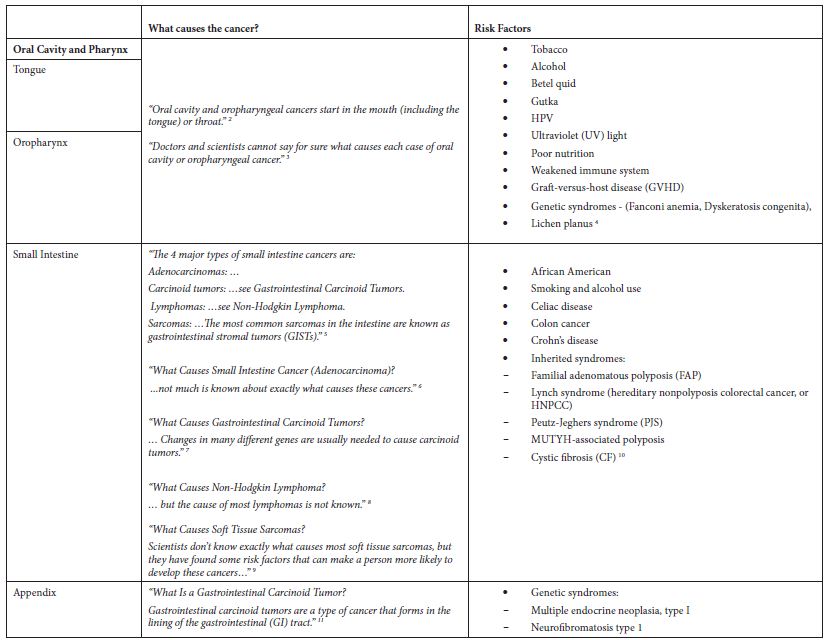
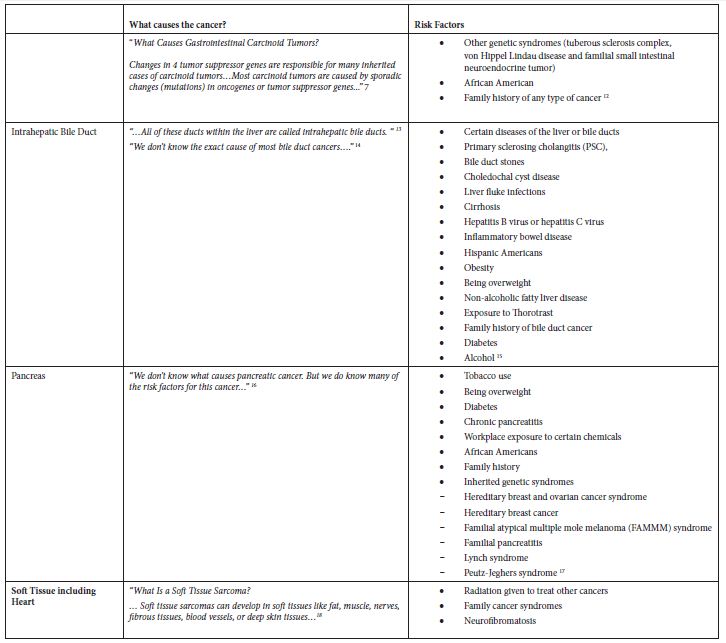
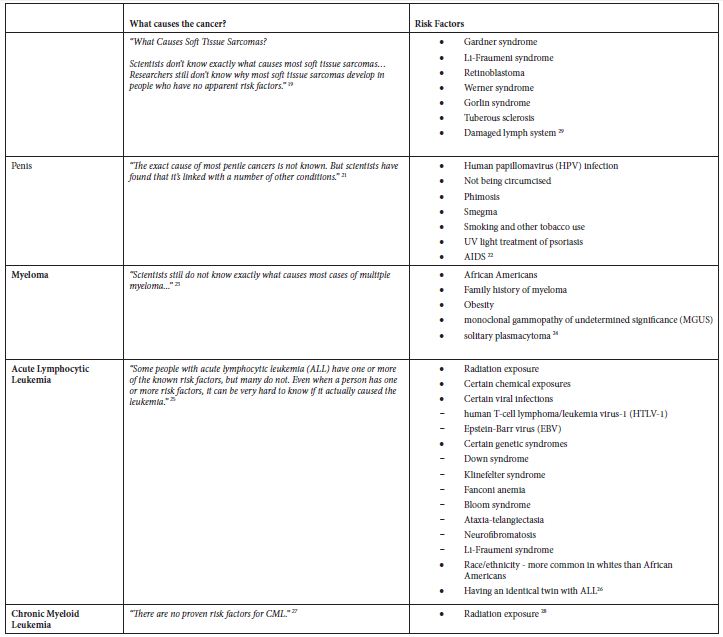
Starting with all 102 groups of cancers from the SEER database, we compiled data for incidence, survival rate, and trend. We added data on whether the cancers had recommended screening guidelines. Our selection criteria for cancer groups representing a health burden were groupings that do not have recommended screening guidelines, had a positive APC over the 6-year period (2011 to 2016), and had a 5-year relative survival rate of less than 70%. From the cancers meeting all three criteria, we removed groupings that were poorly defined, groupings containing “Other” or “Not Otherwise Specified”, and groupings that were too broadly defined (e.g., “Female Genital System”). We removed “Liver and Intrahepatic Bile Duct” since it includes the sub-category “Liver” that did not meet the criteria, but the sub-category “Intrahepatic Bile Duct” is in the final list (Table 1). We implemented the primary exclusion criterion by reviewing the websites of the American Cancer Society (ACS) (Cancer.org) and the National Cancer Institute (NCI) (Cancer.gov) to identify risk factors, causal and non-causal, for each of the cancers initially selected based on epidemiological measures. None of the cancers that met the inclusion criteria had established causal factors, so none were excluded (Table 2).
Table 1: Cancers meeting inclusion criteria
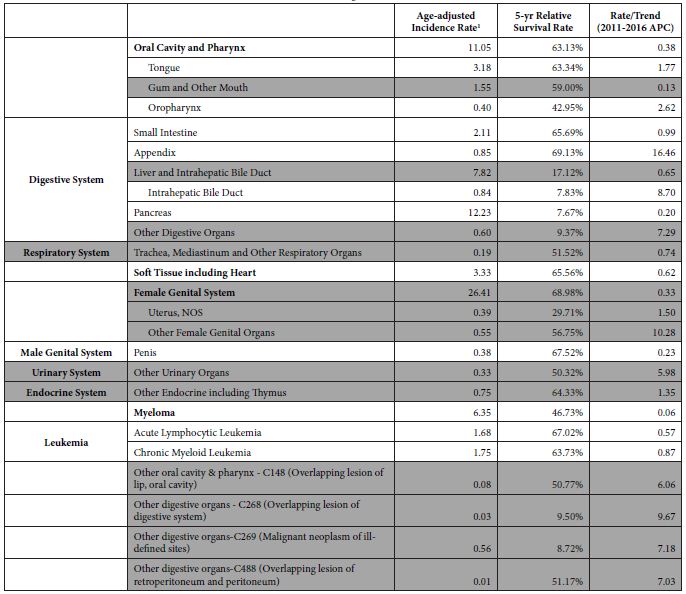
1Rate per 100,000 population, age-adjusted to the 2000 U.S. standard population.
Shaded groupings were removed for reasons stated above
Table 2: Application of exclusion criterion using information from the ACS website



Results
The main epidemiological measures for the 12 groupings of poorly understood cancers are presented in Table 1. The grouping of “Oral Cavity and Pharynx” is a major grouping with sub-groupings “Tongue” and “Oropharynx”, and all three are in the final list. There are four groupings of the digestive system – “Small Intestine”, “Appendix”, “Intrahepatic Bile Duct”, and “Pancreas”. There are two leukemias – “Acute Lymphocytic Leukemia” and “Chronic Myeloid Leukemia”. The other groupings are “Soft Tissue including Heart”, “Penis”, and “Myeloma”.
The cancers included in the final list have varying statistics (Table 1). The age-adjusted incidence rates of poorly understood cancers in the final list range from 0.40 to 12.23 cases per year per 100,000 population. The incidence rates for all the 102 original groupings ranged from 0.00063 to 85.28 cases per year per 100,000 population. The final list of cancers has 5-year survival rates ranging from 7.67% for Pancreatic Cancer to 69.13% for Cancer of the Appendix. Cancer of the Appendix has the highest upward incidence trend (APC=16.46), followed by Intrahepatic Bile Duct (APC=8.70), Oropharynx (APC=2.62), and Tongue (APC=1.76). The other cancers have upward incidence trends of less than 1.00% APC. While there are some known risk factors for these cancers, there are no known causal risk factors.
Some of these cancers, such as soft tissue cancer including heart, have a more robust set of potential risk factors in the ACS classification of risk factors but a substantially larger number of potential risk factors classified by NCI. Others like “Acute Lymphocytic Leukemia” have a large number of potential risk factors in both ACS and NCI classifications. Tobacco, infections, radiation, and immunosuppressive medications were stated more as general risk factors for many of these poorly understood cancers. Some cancer-specific risk factors are viruses, diseases, syndromes, and poor nutrition, but the overall opinion is that very little is known about the causes of these cancers.
Discussion
Our study identified 12 cancers as poorly understood because a causal risk factor has not yet been identified. These 12 cancers, though not among the cancers with highest health burden in the United States and worldwide — a ranking mostly reserved for lung, colorectal, prostate, breast and cervical cancer — represent a moderate health burden if their count is taken in aggregate. Therefore, preventing these cancers and improving population health will be possible if we identify their causal risk factors (exposures).
Identifying associations between exposures and cancer can be done through cohort or case-control studies [18, 19]. A cohort study can provide strong evidence of causal associations. ACS’ Cancer Prevention Studies (CPS-I, CPS-II, CPS-3) are large scale, prospective, cohort studies [7]. These studies required large scale recruitment of subjects, survey completion by the subjects, and long follow-up periods. Initially, the aim was to determine the relationship between smoking and mortality from diseases. CPS-3 aims to determine the causes and protectants of cancer by looking at lifestyle, exposure, biology, and environment [7]. The results of CPS-I and II have identified significant factors that affect health and diseases progression. This information identified the areas to focus resources in order to combat diseases. These studies have provided valuable information that has helped to improve health; however, they require significant manpower and follow-up time. CPS-I had 68,000 volunteers in 25 states, a cohort of almost one million participants (men and women) and ran from 1959 through 1972. The CPS-II cohort was established in 1982 through recruitment of 1.2 million men and women in 50 states by 77,000 volunteers. CPS-3, with over 30,000 volunteers, enrolled over 304,000 participants from across the United States and Puerto Rico from 2006 through 2013. CPS-II and CPS-3 are still ongoing [7, 14].
Two common features of the poorly understood cancers identified in this study are they are rare and have low survival rates (< 70%). These features limit the choices of study designs; however, the low survival rates indicate their severity and justify the need for studying these cancers. A cohort study of these cancers would be challenging. The first challenge for studying these cancers is finding a large enough number of eligible, willing subjects to form a reliable study group. Second, based on the long follow-up required, the expected loss of study subjects might make any results obtained unreliable. Third, these challenges would increase the costs of studying these cancers. In addition, any study results obtained might not be useful due to low power. This justifies a case-control approach to investigating these cancers. A case-control approach selects subjects based on the outcome (e.g., presence/absence of one of these rare cancers) and measures the prior exposure event retrospectively. Compared to a cohort study, this approach would require fewer subjects, less time, and less funding.
We intend to use a case-control design and informatic-derived analytical techniques to identify potential risk factors for these poorly understood and somewhat rare cancers. Our aim is to combine various secondary datasets that traditionally have not been analyzed together for the purpose of performing exploratory data analyses and subsequent generation of hypotheses about unknown risk factors for these cancers. We believe this approach is novel due to the use of only secondary data and informatic-derived imputation methods and analyses. Using logistic regression to impute missing attributes in the dataset will produce a more complete dataset with sociodemographic, behavioral, and environmental attributes. The application of geographic information system (GIS) analyses, association mining, cluster analyses, and contrast mining to this dataset could reveal valid relationships.
The term “poorly understood” is often used to describe many different aspects of diseases, ranging from etiology to outcomes. However, criteria for assigning the term to any aspect of disease have not been established. There is research on individual cancer types and sub-types that are termed “poorly understood”, but the publications do not provide objective justification for assigning the term. We believe this approach is also relatively novel due to the use of set measures for selecting poorly understood cancers.
We aim to include in the study multiple types of factors (environmental, behavioral, sociodemographic, clinical) against multiple types of poorly understood cancers as in the Environmental Public Health Tracking Network (EPHTN) of Wisconsin conducted by Hanrahan et al, 2004. The Wisconsin EPHTN was established to generate and test hypotheses for environmental causes of childhood cancers [6]. However, by using more types of factors, this proposed study can also examine interactions of the factors against cancer type(s) in all age groups.
Using data from the Missouri Cancer Registry, University of Missouri (MU) Healthcare, U.S. Census, Behavioral Risk Factor Surveillance System, and the Environmental Protection Agency, we will create datasets that have data on cancer incidence, health care records, demographics, behavioral risk factors, and environmental factors.
We will start by identifying the records of new cases of the cancers of interest in the Missouri Cancer Registry (i.e., incidence cancer cases). We will then identify if these patients also exist in the MU Healthcare electronic health records (EHR). For these matches, we will link and merge the records for the individuals, including cancer diagnosis and all available sociodemographic attributes, in both datasets as well as medications and procedure information from the MU healthcare system dataset. From the EHR dataset, we will also select un-matched patients (non-cancer patients or patients without a cancer of interest) that have similar demographic characteristics to the matched subjects. The selected patients will form control pools from which we will select our controls.
The data for the individual subjects and controls will lack values for many sociodemographic, behavioral, and environmental attributes of interest in this research but will have geographic identifiers that will be used to impute such values. Using demographic, behavioral, and environmental attributes from individuals in similar sociodemographic categories as the study cancer cases but from other datasets and the geographical identifiers available in both datasets, an imputation process will be used to ascribe values of these attributes to the study cancer cases. These geographic identifiers will be used to ascribe extrapolated and imputed values of demographic and environmental attributes to the cancer cases. We will use logistic regression for this imputation analysis. The resulting datasets will be significantly enriched for hypothesis generation analyses of the associations between cancer and potential risk factors that otherwise could not have been studied. This type of analytical approach is only hypothesis generating because of the many possible biases originating from the extrapolation and imputation processes.
We will also analyze the enriched dataset using geographic information system (GIS) analyses, association mining, cluster analyses, contrast mining, and statistical analyses. GIS analyses can determine the proximity to regulated environmental activities. Association mining will identify associations between cancer(s) and the attributes within the dataset. Cluster analysis will be used to group cancers based on similarities and might identify different cancers that have one or more common factors. Contrast mining will be used to identify differences among different cancers and cancer groups by comparing the factors associated with each. Statistical analyses will be used to model relationships within the dataset and determine the odds ratios and 95% confidence intervals for associations within the dataset.
The results of this design and analyses approach are expected to benefit prevention and control strategies for these rare cancers. Currently, the rarity of these cancers and the prohibitive costs of established epidemiological studies of cancer etiology make it infeasible for research-funding institutions to support studies of these cancers. The findings of this study and the accompanying big-data driven case-control study should help guide research agencies’ decisions to fund further investigation into specific cancers and risk factors relationships they postulate.
If progress is not made regarding cancer prevention and control, the medical cost of cancer in the U.S. could rise to $207 billion by 2020 [2]. The increasing burden of cancer will have an even greater impact on low- and middle-income countries. These countries already bear the burden of 70% of cancer deaths, are at a financial disadvantage due to the significant financial cost of cancer, and lack the resources to detect and adequately treat cancer [1, 23].
Conclusion
This study is a first step toward our overall research goal to identify possible causal risk factors for poorly understood cancers. This first step systematically identified the cancer types that are severe and trending up but for which the risk factors are poorly understood. A major limitation is the low incidence for these cancers. This low power makes it highly infeasible to study these specific cancers using cohort studies. We propose a novel approach to generate hypotheses for the associations of these poorly understood cancers with multiple risk factors. This approach circumvents historical limitations of cost and feasibility of implementation that culminated with these cancers being currently classified as poorly understood.
We propose to use current health information technology and data to develop methods to overcome the limitations of the traditional epidemiological approach and identify possible risk factors for these poorly understood cancers. A big-data driven approach to identifying risk factors maximizes the size of the study group, is more cost effective than the traditional approach, eliminates the problem of lost study subjects, and reduces the time to obtain results. We believe it is the least costly and most feasible approach to identify risk factors for poorly understood cancers.
References
- Cancer (2012, September 8) World Health Organization. https://www.who.int/news-room/fact-sheets/detail/cancer.
- Cancer costs projected to reach at least $158 billion in 2020 (2011, January 11) National Institutes of Health (NIH). https://www.nih.gov/news-events/news-releases/cancer-costs-projected-reach-least-158-billion-2020
- Cancer Facts & Figures 2018 | American Cancer Society. (2018) Cancer Facts & Figures 2018. https://www.cancer.org/research/cancer-facts-statistics/all-cancer-facts-figures/cancer-facts-figures-2018.html
- Cancer Prevention Overview (PDQ®)–Patient Version—National Cancer Institute (nciglobal,ncienterprise) (2009, June 22) [PdqCancerInfoSummary]. https://www.cancer.gov/about-cancer/causes-prevention/patient-prevention-overview-pdq
- CDC – Expected New Cancer Cases and Deaths in 2020 (2019, January 31). https://www.cdc.gov/cancer/dcpc/research/articles/cancer_2020.htm
- Hanrahan, L. P., Anderson, H. A., Busby, B., Bekkedal, M., Sieger, T., Stephenson, L., Knobeloch, L., Werner, M., Imm, P., & Olson, J (2004) Wisconsin’s Environmental Public Health Tracking Network: Information Systems Design for Childhood Cancer Surveillance. Environmental Health Perspectives 112(14), 1434–1439. https://doi.org/10.1289/ehp.7150 [crossref]
- History of the Cancer Prevention Studies. (n.d.). American Cancer Society. Retrieved October 7, 2019, from https://www.cancer.org/research/we-conduct-cancer-research/behavioral-and-epidemiology-research-group/history-cancer-prevention-study.html
- Humans, I. W. G. on the E. of C. R. to. (2010) Summary of Data Reported. In Alcohol Consumption and Ethyl Carbamate. International Agency for Research on Cancer. https://www.ncbi.nlm.nih.gov/books/NBK326555/ [crossref]
- Late-stage cancer detection in the USA is costing lives—The Lancet (2010, December 4). The Lancet. https://www.thelancet.com/journals/lancet/article/PIIS0140-6736(10)62195-2/fulltext
- Limit Alcohol Consumption. (n.d.). American Institute for Cancer Research. Retrieved October 7, 2019, from https://www.aicr.org/cancer-prevention/recommendations/limit-alcohol-consumption/
- Moolgavkar, S. H., Holford, T. R., Levy, D. T., Kong, C. Y., Foy, M., Clarke, L., Jeon, J., Hazelton, W. D., Meza, R., Schultz, F., McCarthy, W., Boer, R., Gorlova, O., Gazelle, G. S., Kimmel, M., McMahon, P. M., de Koning, H. J., & Feuer, E. J (2012) Impact of Reduced Tobacco Smoking on Lung Cancer Mortality in the United States During 1975–2000. JNCI Journal of the National Cancer Institute 104(7), 541–548. https://doi.org/10.1093/jnci/djs136
- Nelson, D. E., Jarman, D. W., Rehm, J., Greenfield, T. K., Rey, G., Kerr, W. C., Miller, P., Shield, K. D., Ye, Y., & Naimi, T. S (2013) Alcohol-Attributable Cancer Deaths and Years of Potential Life Lost in the United States. American Journal of Public Health 103(4), 641–648. https://doi.org/10.2105/AJPH.2012.301199 [crossref]
- Novello, A. C. (1990) Surgeon General’s report on the health benefits of smoking cessation. Public Health Reports 105(6), 545–548. [crossref]
- Patel, A. V., Jacobs, E. J., Dudas, D. M., Briggs, P. J., Lichtman, C. J., Bain, E. B., Stevens, V. L., McCullough, M. L., Teras, L. R., Campbell, P. T., Gaudet, M. M., Kirkland, E. G., Rittase, M. H., Joiner, N., Diver, W. R., Hildebrand, J. S., Yaw, N. C., & Gapstur, S. M (2017) The American Cancer Society’s Cancer Prevention Study 3 (CPS-3): Recruitment, study design, and baseline characteristics. Cancer 123(11), 2014–2024. https://doi.org/10.1002/cncr.30561. [crossref]
- Proctor, R. N (2012) The history of the discovery of the cigarette–lung cancer link: Evidentiary traditions, corporate denial, global toll. Tobacco Control 21(2), 87–91. https://doi.org/10.1136/tobaccocontrol-2011-050338.
- Recommendations (2017, September) U. S. Preventive Services Taskforce. https://www.uspreventiveservicestaskforce.org/uspstf/topic_search_results?topic_status=P&category%5B%5D=15&type%5B%5D=5&searchterm=cancer+screening
- Risk Factors: Infectious Agents – National Cancer Institute (nciglobal,ncienterprise) (2015, April 29) [CgvArticle]. https://www.cancer.gov/about-cancer/causes-prevention/risk/infectious-agents.
- Rothman, Kenneth J (1998a) Case-Control Studies / Kenneth J. Rothman, Sander Greenland. In Modern epidemiology / Kenneth J. Rothman, Sander Greenland ; with 15 contributors (2nd ed., pp. 93–114). Lippincott-Raven.
- Rothman, Kenneth J (1998b) Cohort Studies / Kenneth J. Rothman, Sander Greenland. In Modern epidemiology / Kenneth J. Rothman, Sander Greenland ; with 15 contributors (2nd ed., pp. 79–92). Lippincott-Raven.
- Schütze, M., Boeing, H., Pischon, T., Rehm, J., Kehoe, T., Gmel, G., Olsen, A., Tjønneland, A. M., Dahm, C. C., Overvad, K., Clavel-Chapelon, F., Boutron-Ruault, M.-C., Trichopoulou, A., Benetou, V., Zylis, D., Kaaks, R., Rohrmann, S., Palli, D., Berrino, F., … Bergmann, M. M (2011). Alcohol attributable burden of incidence of cancer in eight European countries based on results from prospective cohort study. BMJ 342. https://doi.org/10.1136/bmj.d1584.
- pdf. (n.d.). Retrieved June 7, 2020, from https://seer.cancer.gov/about/factsheets/SEER_Overview.pdf.
- Site Recode—SEER Recodes. (n.d.). Surveillance, Epidemiology, and End Results Program. Retrieved October 7, 2019, from https://seer.cancer.gov/siterecode/icdo3_dwhoheme/index.html.
- Torre, L. A., Siegel, R. L., Ward, E. M., & Jemal, A. (2016) Global Cancer Incidence and Mortality Rates and Trends—An Update. Cancer Epidemiology and Prevention Biomarkers 25(1), 16–27. https://doi.org/10.1158/1055-9965.EPI-15-0578 [crossref]
- Ultraviolet (UV) radiation and skin cancer (2017, October 16). https://www.who.int/news-room/q-a-detail/ultraviolet-(uv)-radiation-and-skin-cancer. [crossref]
- What Are the Risk Factors for Lung Cancer? | CDC (2019, November 18). https://www.cdc.gov/cancer/lung/basic_info/risk_factors.htm
- WHO | Cancer prevention (2019) WHO; World Health Organization. http://www.who.int/cancer/prevention/en/
- Why is early diagnosis important? (2015, April 2) Cancer Research UK. https://www.cancerresearchuk.org/about-cancer/cancer-symptoms/why-is-early-diagnosis-important
- Worldwide cancer statistics (2019). Cancer Research UK. https://www.cancerresearchuk.org/health-professional/cancer-statistics/worldwide-cancer